
Interaktivní simulátor neuronových sítí
Uživatelská dokumentace
Obsah
2 Instalace a spuštění iSNS 13
2.1 Kompletní distribuce iSNS s Java RE pro operační systém Windows 13
2.2 Kompletní distribuce iSNS bez Java RE 13
5.3 Omezení spojená s ukládáním projektu 23
6.4 Ukládání a načítání dat 25
7.2 Ukládání a načítání sítě 29
7.4 Sítě typu Backpropagation 31
7.4.1 Výpočet výstupu a potenciálu 32
7.4.4 Backpropagation algoritmus - MyBPLearning 35
7.5.2 Panel Kohonenovy mapy 42
7.5.3 Učení a algoritmus MyKohonenLearning 43
7.5.3.2 Algoritmus MyKohonenLearning 46
7.6.3 Panel sítě typu Hopfield 52
7.6.5 Nastavení / uložení současného stavu sítě 54
7.6.6 Zašumění současného stavu sítě 54
7.6.8.1 Algoritmus MyRecollection 58
8.1 Vytvoření vizualizačního modulu 63
8.2 Typy vizualizačních modulů 65
8.2.11 TimeSeries Line Chart 71
8.2.12 TimeSeries Area Chart 72
8.2.13 TimeSeries Step Chart 73
8.3 Ovládání vizualizačních modulů 73
8.4 Odstranění vizualizačního modulu 75
9.1 Vytvoření nového algoritmu 78
9.2 Otevření existujícího algoritmu 81
9.7 Několik doporučení pro psaní uživatelských algoritmů 88
9.7.1 Vytváření položek přístupných z programu 88
9.7.2 Definování míst pro krokování 89
10.1 Vytvoření sítě a dat a naučení funkce OR 90
10.2 Různé možnosti zásahů do sítě 94
10.2.1 Změna prahu určitého neuronu 94
10.2.3 Změna parametru přechodové funkce 95
10.3 Použití vizualizačních modulů při učení 95
10.3.1 Vizualizace průběhu chybové funkce 95
10.3.2 Zobrazení všech výstupů určité vrsty sítě 96
10.4 Vytvoření a použití vlastní přechodové funkce 97
10.5 Vlastní přechodová funkce II – s uživatelským parametrem 99
10.6 Pozměnění algoritmu učení a jeho použití 101
10.7 Rozdělení vstupních dat pomocí Kohonenovy mapy 104
10.8 Rozpoznávání zašuměných znaků pomocí sítě typu Hopfield 108
Program iSNS je simulátor neuronových sítí s podporou pro vizualizaci a interaktivitu, určený zejména pro výukové účely.
Umožňuje vytvářet neuronové sítě typu Backpropagation, Kohonenovy mapy a Hopfield, které zobrazuje pomocí 3D vizualizací, čímž nabízí jedinečný pohled na jejich práci. Má vestavěný editor pro data, takže lze přímo v programu snadno spravovat (tj. vytvářet, načítat, ukládat a upravovat) učící nebo testovací data a výstupy sítí, které je možné velmi jednoduše předkládat vytvořeným sítím. Podporuje import a export dat z/do přenositelných formátů jakými jsou XML, CSV nebo různé obrazové formáty, dokáže tedy spolupracovat s libovolnými jinými aplikacemi, jež tyto formáty znají. Součástí je též editor algoritmů, který umožňuje vytvářet nové učící algoritmy nebo měnit kód vestavěných algoritmů, a tak vznikne velmi jednoduchým způsobem algoritmus šitý na míru uživatele.
Několika málo kliknutími lze snadno vytvořit například síť typu Backpropagation.
Uživatel si může síť prohlížet pomocí 3D vizualizace nebo
procházet přímo její datovou strukturou, učit ji vlastním nebo již
připraveným algoritmem, nebo ji třeba úplně změnit (tj. přidávat
a odebírat neurony i celé vrstvy).
Je velmi snadné naučit svou síť typu Backpropagation například funkci OR. Stačí připravit učící data:

spolu s nimi vybrat učící algoritmus,

nakonec si rozdělit plochu na oblasti, aby bylo vidět vše najednou, a pak jen spustit učení:

Program obsahuje velké množství různých způsobů vizualizace dat (např. sloupcové, koláčové nebo čárové grafy), které přináší další pohled na práci sítě a zkušenějším uživatelům tak umožní najít případné nové souvislosti. Použití grafů pro sledování libovolných dat sítě je opět velmi jednoduché, a protože se zobrazují v záložkách, lze je přesouvat mezi různými oblastmi tak, aby celkový pohled na aktuální projekt byl pro uživatele co nejpřehlednější.
Příkladem může být následující sloupcový graf:

nebo
graf plošný, který poskytne zcela jiný pohled do sítě:

iSNS klade důraz na přehlednost a jednoduchost ovládání. Jak je vidět výše, pracovní plocha umožňuje plnou konfigurovatelnost - lze ji libovolně dělit na menší oblasti a pomocí Drag&Drop (přetažením myší) mezi nimi přemisťovat jednotlivé panely v záložkách. Uživatel si tak může uspořádání pracovní plochy změnit k obrazu svému.
Neméně důležitou vlastností iSNS je perzistence. To znamená, že umožňuje uchovat nejenom data, sítě a algoritmy, ale i rozmístění pracovní plochy, vizualizační moduly a vazby mezi jednotlivými prvky. Jinými slovy: vše, co si uživatel připraví (sítě, data, algoritmy a rozmístění panelů na pracovní ploše), lze uložit do souboru a poté zpět načíst.
iSNS je napsán kompletně v Javě, není tedy vázán na konkrétní platformu. Může si ho tedy vyzkoušet každý, kdo disponuje nějakým ne příliš starým počítačem. Byl úspěšně otestován na Windows/x86, Linux/x86 a Linux/PowerPC.
Neuronové sítě jsou oborem umělé inteligence, napodobují práci mozku.
Lidský nervový systém je považován za nejsložitější a nejvšestrannější výsledek evoluce. Ovládá všechno od základních reflexů až po schopnosti učení a paměť. Jeho struktura napovídá, jak takového výkonu dosáhnout. Narozdíl od počítačů, které pracují primárně sekvenčně, nervový systém je masivně paralelní. Lidský nervový systém obsahuje okolo sta miliard procesorů - neuronů, každý je spojen s tisíci svých sousedů.
Neuronové sítě napodobují biologické neuronové sítě nalezené v mozku. Skládají se z elementů - neuronů, které jsou pospojovány obdobně jako jejich biologické předlohy. Neurony paralelně spolupracují a produkují výstup. Protože neurony pracují kolektivně, dokáže neuronová síť plnit svou funkci i v případě, že některé neurony nefungují - jinými slovy je robustní v toleranci k chybám. Z ukázkových příkladů se dokáží učit řešit složité problémy a zobecnit získanou znalost tak, že vyřeší i před tím neviděné případy.
Jsou užitečné tam, kde mají konvenční počítačové systémy problémy jako je rozpoznávání vzorů nebo predikce trendů. Nalezly uplatnění v mnoha oblastech od předpovědi vývoje trhu až po diagnostiku v medicíně nebo kontrolu kvality.
Spusťte samorozbalovací ZIP archív a v otevřeném okně zvolte cílovou cestu instalace iSNS. Adresář iSNS se vytvoří automaticky. Po stisknutí tlačítka OK se obsah archívu rozbalí do Vámi zadané cesty. Je potřeba mít na cílovém disku alespoň 110 MB volného místa. Archív obsahuje Java Runtime Environment 1.5 včetně všech potřebných knihoven a Java3D.
Spuštění iSNS se provádí pomocí spustitelného souboru iSNS.exe v adresáři programu.
Rozbalení ZIP archívu vyžaduje 17 MB volného místa na disku. Archív obsahuje všechny potřebné knihovny a Java3D pro Windows.
Pro běh aplikace je potřeba mít nainstalováno Java Runtime Environment 1.5 a vyšší. Ke spuštění iSNS je potřeba knihovna Java3D, pro OS Windows je knihovna součástí distribuce. Binární distribuce knihovny Java3D pro Linux/x86, Solaris/x86, Solaris/SPARC, MacOS X je k dispozici ke stažení na stránkách [https://java3d.dev.java.net/binary-builds.html]. Pro ostatní systémy a architektury je možné knihovnu Java3D zkompilovat ze zdrojových kódů, jedná se totiž o open source projekt.
Spuštění iSNS se provádí pomocí iSNS.jar - na operačním systému, kde je nastavená asociace JAR souboru pro Java RE (např. Windows), stačí spustit iSNS.jar. Na systémech, které nemají nastavenou asociaci pro JAR soubory, je potřeba iSNS spustit příkazem java -jar isns.jar.
Minimální konfigurace:
800 MHz procesor,
256 MB operační paměti,
110 MB volného místa na disku pro kompletní instalaci.
Doporučená konfigurace:
1,5 GHz procesor,
512 MB operační paměti,
grafická karta s podporou hardwarové 3D akcelerace,
110 MB volného místa na disku pro kompletní instalaci.
Po spuštění iSNS se otevře hlavní okno (viz následující obrázek) a vytvoří se prázdný projekt. Projekt v iSNS reprezentuje data, sítě, uživatelské algoritmy a rozmístění pracovní plochy - jako celek lze uložit na disk.
Sítěmi se rozumí neuronové sítě (např. Kohonenova mapa), data jsou vstupy a výstupy sítí (např. matice čísel jako učící data), algoritmus lze přiřadit k síti, která ho použije např. jako učící algoritmus.

Hlavní
okno obsahuje:
v horní části menu,
v levé části manažery (Data, Networks, Algorithms),
v dolní části stavový řádek,
zbytek vyplňuje pracovní plocha.
Menu je základním ovládacím prvkem aplikace. Nabízí služby jako je práce s projektem, daty, sítěmi, algoritmy nebo vizualizačními moduly. Pro nejčastěji používané operace menu jsou k dispozici různé „zkratky“ (tlačítka, kontextová menu, ...) - popsané v místě použití. Kompletní popis menu viz kapitola 12 Dodatek: Popis menu.
Manažery (manažer dat, manažer sítí, manažer algoritmů) slouží ke správě dat, sítí a uživatelských algoritmů. Obsahují seznam aktuálně vytvořených/načtených/importovaných datových proměnných, sítí nebo algoritmů (v podobě uživatelských proměnných) - právě s těmito sítěmi je možno pracovat, právě tato data a algoritmy jsou pak k dispozici např. při učení. Všechny tři manažery mají tlačítka a kontextová menu s nejčastěji používanými operacemi pro urychlení práce. Podrobnější informace lze nalézt v kapitolách 4.1 Manažer dat, 4.2 Manažer sítí a 4.3 Manažer algoritmů.
Ve stavovém řádku se zobrazují informační a chybová hlášení.
Pracovní plocha poskytuje prostor pro další panely, které si chce uživatel otevřít v záložkách (např. panel sítě, editor dat, editor algoritmů, ...). Je plně konfigurovatelná - lze ji snadno rozdělit na menší části (tzv. oblasti), měnit jejich velikost, a panely mezi nimi pomocí Drag&Drop přesouvat. Jedna oblast může obsahovat i více záložek s panely. Uživatel si tak může sám vybrat, co a kde chce v jednu chvíli vidět. Jak konkrétně se plocha dělí a více informací viz kapitola 4.4 Pracovní plocha.

Manažer dat zobrazuje seznam datových proměnných projektu. Jedná se o vektory, matice, případně další datové struktury, se kterými neuronové sítě pracují.
V
dolní části jsou tlačítka Create data
![]() ,
Load data
,
Load data
![]() ,
Save data
,
Save data
![]() a
Remove data
a
Remove data
![]() ,
která představují zkratky pro nejčastěji používané operace z menu
Data.
,
která představují zkratky pro nejčastěji používané operace z menu
Data.
Kliknutí levým tlačítkem myši na jméno proměnné ze seznamu slouží k označení konkrétní datové proměnné, se kterou se bude dále pracovat (např. mazat).
Dvojklik levým tlačítkem myši na jméno proměnné ze seznamu otevře editor, který zobrazí obsah zvolené proměnné, případně ji umožní editovat.
Kliknutí pravým tlačítkem myši na jméno proměnné ze seznamu označí proměnnou a vyvolá kontextové menu s funkcemi z menu Data.
Manažer sítí zobrazuje seznam sítí projektu. V jednom projektu může být najednou otevřeno více sítí a to libovolného ze tří podporovaných typů: Backpropagation, Kohonen či Hopfield.
V
dolní části jsou tlačítka Create network
![]() ,
Load network
,
Load network
![]() ,
Save network
,
Save network
![]() a
Remove network
a
Remove network
![]() ,
která představují zkratky pro nejčastěji používané operace z menu
Network.
,
která představují zkratky pro nejčastěji používané operace z menu
Network.
Kliknutí levým tlačítkem myši na jméno sítě ze seznamu slouží k označení konkrétní sítě, se kterou se bude dále pracovat (např. mazat).
Dvojklik levým tlačítkem myši na jméno sítě ze seznamu otevře panel sítě, který síť zobrazuje a umožňuje s ní dále pracovat (učit, měnit, ...).
Kliknutí levým tlačítkem myši na jméno sítě ze seznamu se současně stisknutou klávesou Shift otevře editor dat, který umožňuje procházet datové struktury, jež síť tvoří.
Kliknutí pravým tlačítkem myši na jméno sítě ze seznamu označí proměnnou a vyvolá kontextové menu s funkcemi z menu Network.
Pokud pracujeme s různými verzemi sítě, zobrazuje se v manažeru sítí strom verzí. Dvojklik na verzi způsobí kromě otevření panelu sítě označení verze za aktuální (a tedy v panelu sítě se objeví právě tato verze sítě). Více o verzích a jejich použití viz kapitola 7.7 Verzování.
Primárním úkolem manažeru algoritmů je přehledné hierarchicky uspořádané zobrazení algoritmů formou stromu. Zobrazují se zde pouze algoritmy, které jsou právě otevřené v projektu, tzn. že je lze editovat.
Manažer dále nabízí možnost „rychlé práce“ s algoritmy pomocí kontextového menu a tlačítek, které obsahují nejpoužívanější akce nad algoritmy.
Strom algoritmů
Struktura: Algoritmy jsou uspořádané ve stromu o 3 patrech. Nejvyšší uzly představují třídy algoritmů (Backpropagation, Kohonen, Recollection a TransferFunction). Druhá vrstva uzlů jsou uživatelské algoritmy (zobrazují se jejich jména), které jsou přiřazeny pod příslušné třídy algoritmů. A poslední vrstva, tj. listy, zobrazuje konkrétní metody daného uživatelského algoritmu (zobrazují se jména metod).
Práce se stromem: Tlačítka a kontextové menu „rychlé práce“ s algoritmy jsou přístupná dle toho, zda je či není označen konkrétní uživatelský algoritmus (tj. prostřední patro uzlů ve stromu). Dvojklik na tento algoritmus nebo na třídu algoritmů zabalí nebo rozbalí celý svůj podstrom. Dvojklik na metodu, tj. na list stromu, pak otevře editor zvolené metody v příslušné oblasti (v novém projektu je tato oblast jen jedna, jak vytvořit nové oblasti viz kapitola 4.4 Pracovní plocha). Editor metod lze také otevřít tak, že se metoda přetáhne do zvolené oblasti plochy (Drag&Drop).
Kontextové menu
Vyvolání: Kontextové menu lze vyvolat stisknutím pravého tlačítka myši kdekoliv v manažeru algoritmů.
Obsah odpovídá menu pro algoritmy a je vždy závislý na tom, zda je ve stromu algoritmů označen uživatelský algoritmus či nikoliv.
Tlačítka
Nabízí „rychlou volbu“ nejpoužívanějších operací nad algoritmy.
Popis tlačítek:
![]() ...
vytvoří nový algoritmus (kapitola 9.1 Vytvoření nového algoritmu),
...
vytvoří nový algoritmus (kapitola 9.1 Vytvoření nového algoritmu),
![]() ...
otevře existující algoritmus ze souboru (kapitola 9.2 Otevření existujícího algoritmu),
...
otevře existující algoritmus ze souboru (kapitola 9.2 Otevření existujícího algoritmu),
![]() ...
uloží celý algoritmus, tj. všechny jeho právě editované metody
(kapitola 9.3 Uložení algoritmu); položka je přístupná, jen pokud
je ve stromu algoritmů označen uživatelský algoritmus,
...
uloží celý algoritmus, tj. všechny jeho právě editované metody
(kapitola 9.3 Uložení algoritmu); položka je přístupná, jen pokud
je ve stromu algoritmů označen uživatelský algoritmus,
![]() ...
odstraní algoritmus z projektu, ale neodstraní jeho zdrojový
soubor (kapitola 9.4 Odstranění algoritmu); položka je přístupná,
jen pokud je ve stromu algoritmů označen uživatelský algoritmus.
...
odstraní algoritmus z projektu, ale neodstraní jeho zdrojový
soubor (kapitola 9.4 Odstranění algoritmu); položka je přístupná,
jen pokud je ve stromu algoritmů označen uživatelský algoritmus.
Celkový náhled

Plochu lze dělit horizontálně, resp. vertikálně, na další oblasti pomocí kontextového menu Separate horizontally, resp. Separate vertically. Nově vytvořené oblasti oddělí sloupec, kterým lze posouvat a měnit tak velikost oblastí. Nové oblasti je možné zavřít pomocí ClosePane. Pokud oblast již obsahuje záložku, je nutné pro další dělení vyvolat kontextové menu nad seznamem záložek v dané oblasti, nikoliv nad obsahem záložky.

Každá oblast může obsahovat libovolný počet záložek, které lze mezi oblastmi přenášet myší (Drag&Drop, táhni a pusť). Díky této vlastnosti lze plochu přizpůsobit tak, aby bylo možné sledovat několik záložek najednou. Záložky jsou vytvářeny automaticky v hlavní (levé horní) oblasti po dvojkliku na objekt v libovolném manažeru, záložka tak obsahuje panel pro manipulaci s daným objektem, nebo po vytvoření nové vizualizace v menu Visualization. Vytvoření záložky v jiné oblasti lze docílit přetažením objektu z manažeru nad libovolnou oblast, nová záložka pro objekt se vytvoří jen v případě, kdy není pro daný objekt již otevřen panel v jiné záložce. Vizualizaci lze vytvořit přímo v libovolné oblasti pomocí kontextového menu Visualization otevřeného nad danou oblastí. Záložky se zavírají pomocí křížku na pravé straně ouška záložky.
Stavový řádek ve spodní části okna informuje o poslední provedené akci, případně zobrazuje chybové hlášení. Informace v něm zmizí po uplynutí 10 sekund.
Ikona
![]() vedle menu Help slouží pro prohledávání menu. Po kliknutí na
ikonu se v menu zobrazí textové pole, do kterého lze napsat název
hledané položky menu. Po stisknutí klávesy Enter je prohledáno
menu a vedle textového pole se vytvoří nová tlačítka (počet tlačítek
je roven počtu menu položek obsahujících hledaný text). Šedivá
tlačítka nelze stisknout - reprezentují menu položku, kterou nyní
nelze vybrat. Po stisknutí ostatních tlačítek se otevře menu a označí
menu položka, která obsahuje hledaný text.
vedle menu Help slouží pro prohledávání menu. Po kliknutí na
ikonu se v menu zobrazí textové pole, do kterého lze napsat název
hledané položky menu. Po stisknutí klávesy Enter je prohledáno
menu a vedle textového pole se vytvoří nová tlačítka (počet tlačítek
je roven počtu menu položek obsahujících hledaný text). Šedivá
tlačítka nelze stisknout - reprezentují menu položku, kterou nyní
nelze vybrat. Po stisknutí ostatních tlačítek se otevře menu a označí
menu položka, která obsahuje hledaný text.
Ačkoliv lze v programu iSNS obsah jednotlivých manažerů - tedy datové proměnné, sítě a algoritmy - samostatně ukládat do souborů, hlavní jednotkou pro zajištění persistence je tzv. projekt. Projekt reprezentuje nejenom všechna používaná data, sítě a algoritmy, ale také rozmístění pracovní plochy a je možné jej jako celek uložit na pevný disk a později opět načíst.
Poznámka: V každém okamžiku práce s programem je v něm otevřen jeden projekt; ihned po spuštění je projekt prázdný.
V případě prvního uložení projektu pomocí menu File -> Save project as... je potřeba zadat umístění (základně adresář projects) a jméno projektu. Pro projekt bude vytvořen nový adresář. Pro přepsání již existujícího projektu lze označit jeho projektový adresář nebo přímo projektový XML soubor (project.xml).

Do adresáře projektu budou uložena veškerá potřebná data (data, sítě, uživatelské algoritmy a rozmístění pracovní plochy), která jsou v aktuálním projektu načtena. Je-li přepisován již existující projekt, je potřeba tuto akci potvrdit. Adresář projektu projde kontrolou, zda neobsahuje již nepoužívaná data a sítě - pokud ano, zobrazí se dotaz na jejich smazání z disku. Pokud nenastane žádná chyba při ukládání dat, zobrazí se informační hlášení o úspěšném uložení projektu.
Dále je možné využít menu File -> Save project, které uloží projekt pod stejným názvem a umístěním jako při posledním uložení, resp. otevření. iSNS má přehled o tom, zda je potřeba aktuální projekt uložit nebo ne (prázdný nebo nezměněný projekt), takže lze projekt uložit i při ukončování programu pomocí menu File -> Exit, zavíracím křížkem okna nebo jiným standardním způsobem.
Otevírání projektu se provádí pomocí menu File -> Open project...

V otevřeném dialogu je potřeba vybrat adresář s projektem nebo přímo projektový soubor (project.xml) v adresáři projektu.
Pokud nenastane žádná chyba při otevírání dat, zobrazí se informační hlášení o úspěšném otevření projektu.
S projektem nelze ukládat na pevný disk aktivní učící algoritmus. Aktivním se myslí takový algoritmus, který zrovna běží nebo je krokován (nikoli zdrojový soubor algoritmu, který je součástí manažeru algoritmů). Projekt uložený v takovém okamžiku, bude později načten bez spuštěného učení a vizualizací, které jsou napojené na proměnné v učícím algoritmu.
Data jsou proměnné vytvořené uživatelem, které mají své jméno a svou hodnotu. Jméno je zadáno uživatelem při vytvoření. Může obsahovat libovolné znaky kromě několika výjimek (hvězdička, dvojtečka, lomítko, zpětné lomítko, ...) - tyto znaky v názvu se při vytváření automaticky nahradí podtržítkem. Možné typy dat jsou matice, vektor a obrázek.
Vektor
Vektor čísel typu double, při vytváření se zadává jeho délka.
Matice
Matice čísel typu double, při vytváření se zadává její výška a šířka. Chápe se jako množina vektorů délky „šířka“; viz kapitola 6.2 Vytváření dat.
Obrázek
Jedná se o datovou strukturu používanou především při práci se sítí typu Hopfield. Vnitřně je reprezentována podobně jako matice jen s tím rozdílem, že připouští pouze dvě hodnoty na každé pozici. Navenek se pak projevuje jako černobílý obrázek - černá barva reprezentuje jednu hodnotu a bílá druhou. Pro upřesnění a vysvětlení použití viz kapitola 7.6.1 Obrázek.
Existují tři možnosti, jak vytvořit data:
kliknutí na
tlačítko
![]() v manažeru dat,
v manažeru dat,
menu Data -> Create data,
Create data v kontextovém menu v manažeru dat.
Zobrazí se dialog, ve kterém je potřeba vybrat typ dat a zadat rozměry a případně změnit jméno (pokud nechceme ponechat automatické).

Takto vytvořená data se objeví v manažeru dat. Pro jejich zobrazení a editaci je třeba na jméno proměnné dvojkliknout.
Jméno musí být v rámci projektu unikátní, tj. není možné pro novou datovou proměnnou použít jméno, které už se v manažeru dat vyskytuje. V případě, že bylo zadáno již používané jméno, zobrazí se dialog pro přejmenování proměnné.

Pokud je zadáno nové jméno, a stisknuto tlačítko OK, data se vytvoří s novým jménem (pokud by ani nové jméno nebylo unikátní, dialog se objeví znovu).
Stisknutí tlačítka Cancel způsobí, že data se nevytvoří.
Po dvojkliknutí na jméno datové proměnné v manažeru dat se otevře záložka s editorem dat. Pokud jsou data typu matice nebo vektor, zobrazí se tabulka s čísly. Kliknutím na vybranou buňku je možné tuto buňku editovat. Editace se ukončí opuštěním buňky (pomocí myši nebo stisknutím klávesy Enter). Pokud je text v buňce ve špatném formátu (není to číslo), zobrazí se chybové hlášení „Bad number format at position [x,y]“ a v buňce zůstane původní text.
V případě dat typu obrázek má editor podobu obdélníku, ve kterém je možné klikáním myší měnit barvu políček z černé na bílou a zpět.
Data je možné uložit různým způsobem:
Save data - uloží data do souboru, do kterého byla ukládána naposledy; pokud ještě ukládána nebyla, chová se stejně jako Save as. Provést tuto akci je možné třemi způsoby:
kliknutí na
tlačítko
![]() v manažeru dat,
v manažeru dat,
menu Data -> Save data,
Save data v kontextovém menu v manažeru dat.
Save data as - uloží data v novém souboru, tzn. součástí ukládání je výběr souboru, do kterého se data uloží. Provést tuto akci je možné dvěma způsoby:
menu Data -> Save data,
Save data v kontextovém menu v manažeru dat.
Soubory s uloženými daty mají koncovku .dat
Uložená data je možné opět načítat do projektu, nezáleží na tom, zda byla uložena v projektu, ve kterém zrovna pracujeme, nebo v jiném.
Načtení dat je možné provést třemi způsoby:
kliknutí na
tlačítko
![]() v manažeru dat,
v manažeru dat,
menu Data -> Load data,
Load data v kontextovém menu v manažeru dat.
Zobrazí se dialog pro výběr datového souboru. Po vybrání souboru se načtená data zobrazí v manažeru dat. Jejich název bude stejný jako název souboru bez koncovky .dat. Pokud by však tento název byl již používán pro nějaká data v manažeru dat, zobrazí se dialog pro zadání nového jména.
Data je možno také smazat, tj. odstranit je z projektu. Smazaná data nebudou v manažeru dat a nebude je možné zobrazit ani editovat. Pokud ale byla předtím uložena (pomocí Save data nebo Save data as, viz kapitola 6.4 Ukládání a načítání dat), soubor s uloženými daty se nesmaže a je možné je zase kdykoli načíst a pracovat s nimi.
Smazání dat se provede jedním z následujících způsobů:
kliknutí na tlačítko
![]() v manažeru dat,
v manažeru dat,
menu Data -> Remove data,
Remove data v kontextovém menu v manažeru dat.
Data, v iSNS reprezentována datovými proměnnými, lze kromě načítání/ukládání v binární podobě (v menu Data funkce Load/Save) také importovat/exportovat do přenositelných textových formátů, které je možné používat nebo vytvářet v jiných aplikacích. Podporované formáty jsou XML a CSV. Speciální možností navíc v případě obrázků je manipulace se soubory s grafickými daty.
CSV neboli Comma Separated Values je jednoduchý formát pro ukládání tabulkových dat. Jednotlivá pole jsou oddělená čárkou, resp. středníkem (v našem případě).
Pro importování dat stačí zvolit v menu Data -> Import data -> CSV a vybrat soubor, jehož obsah odpovídá níže uvedené specifikaci. Bude tak vytvořena nová datová proměnná s daty vybraného souboru.
Pro exportování dat je třeba mít označenou datovou proměnnou, jejíž obsah se bude exportovat; v menu zvolit Data -> Export data -> CSV a zadat název souboru, kam se obsah proměnné uloží.
Specifikace formátu:
první řádek obsahuje libovolný komentář,
druhý řádek obsahuje jméno proměnné,
třetí řádek obsahuje typ (vectorDouble/matrixDouble/picture) a rozměry (délka/výška šířka/výška šířka),
na následujících řádcích jsou vlastní data.
Příklad pro nulovou matici čísel typu double s rozměry 3 x 2 a názvem „moje matice“:
Generated by iSNS - Variable moje matice
moje matice
matrixDouble 3 2
0.0;0.0
0.0;0.0
0.0;0.0
XML neboli Extensible Markup Language je obecný značkovací jazyk, který byl vyvinut a standardizován konsorciem W3C. Umožňuje snadné vytváření konkrétních značkovací jazyků pro různé účely a široké spektrum různých typů dat.
Pro importování dat stačí zvolit v menu Data -> Import data -> XML a vybrat soubor, jehož obsah odpovídá níže uvedené specifikaci. Bude tak vytvořena nová datová proměnná s daty vybraného souboru.
Pro exportování dat je třeba mít označenou datovou proměnnou, jejíž obsah se bude exportovat; v menu zvolit Data -> Export data -> XML a zadat název souboru, kam se obsah proměnné uloží.
Specifikace
formátu:
jméno proměnné je reprezentováno názvem souboru,
vektor: celý vektor je reprezentován elementem <double-array> ... </double-array>, jednotlivé hodnoty jsou v jeho podelementech <double> ... </double>,
matice: skládá se z vektorů, které jsou podelementy elemetu <double-array-array> ... </double-array-array>,
obrázek: celý obrázek je reprezentován elementem <isns.hopfield.Picture> ... </isns.hopfield.Picture>, ten obsahuje tři podelementy <width> ... </width>, <height> ... </height> a <data> ... </data>, vlastní data jsou pak v elementu <double> ... </double> jako podelementy elementu <data> ... </data>.
Příklad pro nulovou matici čísel typu double s rozměry 3 x 2 a názvem „moje matice“:
<double-array-array>
<double-array>
<double>0.0</double>
<double>0.0</double>
</double-array>
<double-array>
<double>0.0</double>
<double>0.0</double>
</double-array>
<double-array>
<double>0.0</double>
<double>0.0</double>
</double-array>
</double-array-array>
Datové proměnné typu obrázek lze navíc, kromě výše popsaných způsobů, také načítat ze souborů známých grafických formátů a ukládat do souborů formátu PNG.
Mezi známé grafické formáty patří např. JPEG, GIF a nebo PNG - konkrétní výčet závisí na podpoře těchto formátů běhovým prostředím Javy (JRE), pod kterým program iSNS běží. V případě, že načítaný obrázek není pouze černobílý, budou všechny pixely nečerné barvy převedeny na bílé.
Pro importování dat stačí zvolit v menu Data -> Import data -> Picture a vybrat soubor některého z podporovaných grafických formátů. Bude tak vytvořena nová datová proměnná typu obrázek s daty vybraného souboru.
Pro exportování dat je třeba mít označenou datovou proměnnou typu obrázek, jejíž obsah se bude exportovat; v menu zvolit Data -> Export data -> Picture a zadat název souboru (s příponou png), kam se obsah proměnné uloží.
Neuronové sítě je možno v programu iSNS vytvářet, učit a testovat, a současně sledovat a měnit jejich vlastnosti. Po vytvoření se síť objeví v manažeru sítí. Pokud chceme se sítí dále pracovat, dvojklikem na její jméno v manažeru sítí si otevřeme panel, ve kterém je síť zobrazena a kde je možné jí též upravovat.
Sledování některých vlastností sítí je možné pomocí vizualizačních modulů - viz kapitola 8 Vizualizační moduly.
Přímé sledování a změny parametrů se dějí v záložce sítě, kde jsou tato data zobrazena. Je zde možné parametry prohlížet a ty, které nejsou read-only (tj. jejich políčko je editovatelné), i měnit. Konkrétněji bude vysvětleno u jednotlivých modelů.
Druhá možnost jak prohlížet a měnit parametry sítě je kliknout v manažeru sítí na vybranou síť se stisknutou klávesou Shift. Tato akce způsobí otevření záložky, ve které je možné přímo procházet celou strukturu sítě a měnit vybrané hodnoty. Viz 10.2 Tutoriály - Různé možnosti zásahů do sítě.
Síť při svém výpočtu používá vždy určitý algoritmus. Ten je možné také upravovat a měnit některé jeho parametry i během výpočtu. Více v kapitole 9 Algoritmy.
Způsob vytvoření nové sítě, především zadávané parametry, závisí na konkrétním modelu sítě, proto je popsán v následujících kapitolách pro jednotlivé modely.
Sítě se v iSNS ukládají ve formátu XML. Výjimku tvoří pouze případ, kdy je síť ukládána jako součást projektu. Pak se z důvodů úspory použije binární formát.
Dialog pro uložení sítě lze vyvolat několika způsoby:
tlačítko
![]() v manažeru sítí (je-li v manažeru sítí nějaká síť vybraná) nebo
v manažeru sítí (je-li v manažeru sítí nějaká síť vybraná) nebo
menu Network -> Save network as..., resp. Save network (je-li v manažeru sítí nějaká síť vybraná) nebo
kliknutí pravým tlačítkem myši v manažeru sítí na nějakou síť (tato bude vybraná) vyvolá kontextové menu -> Save network as..., resp. Save network.

V
dialogu pro uložení sítě je třeba zvolit název souboru, kam se síť
uloží, případně vybrat jiný adresář. Nakonec stisknout tlačítko Save.
Načtení sítě probíhá obdobně, dialog pro načtení sítě lze vyvolat:
tlačítko
![]() v manažeru sítí nebo
v manažeru sítí nebo
menu Network -> Load network... nebo
kliknutí pravým tlačítkem myši kdekoliv v manažeru sítí vyvolá kontextové menu -> Load network...

V dialogu pro načtení sítě je třeba zvolit název souboru, ve kterém je uložena síť, a stisknout tlačítko Open.
Síť lze odstranit několika způsoby:
tlačítko
![]() v
manažeru sítí (je-li v manažeru sítí nějaká síť vybraná) nebo
v
manažeru sítí (je-li v manažeru sítí nějaká síť vybraná) nebo
menu Network -> Remove network (je-li v manažeru sítí nějaká síť vybraná) nebo
kliknutí pravým tlačítkem myši v manažeru sítí na nějakou síť (tato bude vybraná) vyvolá kontextové menu -> Remove network.
Odstraněná síť zmizí ze seznamu v manažeru sítí.
Backpropagation síť (neboli síť typu zpětného šíření, vrstevnatá síť) je neuronová síť, kde neurony tvoří jednotlivé vrstvy. Vahami jsou propojené vždy právě neurony dvou sousedních vrstev. Síť je tvořena vstupní vrstvou, výstupní vrstvou a libovolným počtem skrytých vrstev.

1. pro vstupní vrstvu výstup = vstup
Neurony ve vstupní vrstvě budou mít takový výstup, jakou hodnotu má odpovídající složka vstupního vektoru, tj. výstup (output) i-tého neuronu = input_i
2. Vypočti potenciál: pro každý neuron následující vrstvy
![]()
Potenciál neuronu n tedy je součet výstupů neuronů předcházející vrstvy, násobených vahami, které je spojují s neuronem n, plus práh (bias).
3. výstup = f(potenciál)
Výstup neuronu se spočítá jako přechodová funkce (transfer function) z jeho potenciálu. (f značí přechodovou funkci neuronu, jehož výstup počítáme).
4. takto postupuj až k výstupní vrstvě;
výstup sítě = výstup poslední vrstvy
Při vytváření Backpropagation sítě je třeba zadat topologii - tj. počty neuronů v jednotlivých vrstvách. Váhy se inicializují náhodně, ale je možno zadat z jakého náhodného rozdělení budou hodnoty vah vybírány - na výběr je uniformní a normální (Gaussovo) rozdělení. U uniformního se zadává minimální a maximální hodnota, u normálního střední hodnota a směrodatná odchylka. Je samozřejmě možné hodnoty vah přímo zadat, to se ovšem děje až po vytvoření, kdy je možné kdykoli v panelu sítě změnit hodnoty vah.
Vyvolání dialogu New net je možné 3 způsoby:
tlačítko
![]() v
panelu sítí nebo
v
panelu sítí nebo
menu Network -> Create network... nebo
kliknutí pravým tlačítkem myši v panelu sítí vyvolá kontextové menu -> Create network...

Dialog New net:
Name - uživatelské jméno sítě,
Model - zde je možné zvolit model sítě, tedy nyní Backpropagation net,
Number of Layers - počet vrstev sítě - podle počtu vrstev se mění počet sloupců tabulky udávající počty neuronů v jednotlivých vrstvách,
Numbers of Neurons in Layers - počty neuronů ve vrstvách, nultá vrstva je vstupní, vrstva s nejvyšším číslem je výstupní,
Distribution - náhodné rozdělení, z něhož se inicializují váhy,
Mean a Deviation, resp. Minimum a Maximum - parametry náhodného rozdělení (střední hodnota a odchylka, resp. dolní a horní mez).
Panel sítě slouží k vizualizaci jedné konkrétní sítě a k práci s ní. Je vyvolán dvojklikem na jméno sítě v manažeru sítí.
Poznámka: Pokud je při dvojkliku na jméno sítě v manažeru sítí držena klávesa Shift, otevře se síť v editoru dat, který umožňuje procházet datové struktury, jež ji tvoří.
Poznámka: Situace je trochu složitější při práci s verzemi - viz kapitola 7.7 Verzování.

3D vizualizátor v levé části panelu zobrazuje síť jako jednotlivé neurony a váhy mezi nimi. Barvy znázorňují výstup neuronu nebo (v případě vah) hodnotu váhy, přičemž nejmenší hodnota je znázorněná modře, největší červeně a ostatní odpovídajícími odstíny z přechodu od modré k červené.
Ovládání:
Kliknutím levým tlačítkem myši lze vybírat jednotlivé neurony.
Síť je možné otáčet pohybem myši při stisknutém levém tlačítku.
Posouvat lze síť pohybem myši se stisknutým pravým tlačítkem.
Pohyb myši se stisknutým prostředním tlačítkem způsobí buď přiblížení (při pohybu dolů) nebo oddálení sítě (při pohybu nahoru).
Dvojklik pravým tlačítkem nastaví síť do výchozí polohy.
Vybraný neuron je znázorněn pomocí žlutého kuželu, který kolem něho krouží. O vybraném neuronu se navíc zobrazí další informace a je možné s ním dále pracovat (přidávání a odebírání neuronů a vrstev viz dále v popisu nástrojové lišty). Hodnoty vah vedoucích do aktuálně vybraného neuronu se zobrazují v tabulce pod sítí. Další informace o právě vybraném neuronu jsou v pravé části panelu. Tyto hodnoty je možné nejen prohlížet, ale také měnit.
Zvláštní položkou je přechodová funkce. Jednak je zde možnost vybrat typ funkce - připravené jsou funkce Purelin, tj. y = a*x, LogSig neboli 1 / (1 + exp(-lambda*x)) a ArcTan neboli arcus tangens. Navíc je možné upravovat parametry přechodové funkce - kliknutím na tlačítko se třemi tečkami pod nadpisem transferFunction se zobrazí parametry (má-li vybraná přechodová funkce nějaké), tedy např. u funkce logsig je možné měnit hodnotu parametru lambda.
Poslední částí panelu, nacházející se vpravo dole, je nástrojová lišta, která obsahuje tlačítka pro práci se sítí:
![]() ...
učení sítě;
...
učení sítě;
![]() ...
testování sítě;
...
testování sítě;
![]() ...
reinicializace všech vah;
...
reinicializace všech vah;
![]() ...
přidá neuron do vybrané vrstvy (tj. vrstvy obsahující označený
neuron). Neurony je možné přidávat pouze do skrytých vrstev (aby
byla zachována konzistence se vstupními a výstupními daty);
...
přidá neuron do vybrané vrstvy (tj. vrstvy obsahující označený
neuron). Neurony je možné přidávat pouze do skrytých vrstev (aby
byla zachována konzistence se vstupními a výstupními daty);
![]() ...
odebere neuron z vybrané vrstvy (tj. vrstvy obsahující označený
neuron). Neurony je možné, podobně jako u přidávání, odebírat pouze
ze skrytých vrstev a z pochopitelných důvodů pouze z
vrstev obsahujících víc než jeden neuron;
...
odebere neuron z vybrané vrstvy (tj. vrstvy obsahující označený
neuron). Neurony je možné, podobně jako u přidávání, odebírat pouze
ze skrytých vrstev a z pochopitelných důvodů pouze z
vrstev obsahujících víc než jeden neuron;
![]() ...
přidá novou vrstvu nad vybranou vrstvu. Nelze takto vytvořit novou
vstupní nebo výstupní vrstvu. Počet neuronů v nové vrstvě je nutné
následně zadat v dialogu. Váhy mezi ostatními vrstvami zůstanou
zachovány, nově vzniklé váhy jsou inicializovány stejně jako při
vytvoření sítě;
...
přidá novou vrstvu nad vybranou vrstvu. Nelze takto vytvořit novou
vstupní nebo výstupní vrstvu. Počet neuronů v nové vrstvě je nutné
následně zadat v dialogu. Váhy mezi ostatními vrstvami zůstanou
zachovány, nově vzniklé váhy jsou inicializovány stejně jako při
vytvoření sítě;
![]() ...
odebere vybranou vrstvu. Odebírány mohou být pouze skryté vrstvy.
...
odebere vybranou vrstvu. Odebírány mohou být pouze skryté vrstvy.
Připravený algoritmus MyBPLearning, který je potomkem třídy BPLearning je možné použít k učení Backpropagation sítě. Jedná se o implementaci algoritmu Backpropagation, neboli algoritmu zpětného šíření.
Cílem učení je, aby síť dávala správné výstupy v reakci na předložené vstupy. K učení se používá množina vstupů a jim odpovídajících správných (požadovaných) výstupů. Nenaučená síť dává výstupy, které se liší od požadovaných. Z aktuálního výstupu a požadovaného výstupu se vypočte velikost chyby pomocí tzv. chybové funkce. Následuje adaptace vah, kdy se postupně od výstupní ke vstupní vrstvě upravují váhy v síti tak, aby chyba (pro tento vstup) byla menší.
Následuje podrobnější popis algoritmu.
0. Náhodně inicializuj váhy a prahy
Viz volba náhodného rozdělení vah v kapitole 7.1 Vytvoření nové sítě.
1. Pro každý vstup a odpovídající požadovaný výstup proveď
1.1 Spočti výstupy a potenciály všech neuronů pro daný vstup. (viz výše)
1.2 Pro neurony výstupní vrstvy
![]()
Delta n-tého neuronu ve výstupní vrstvě se tedy spočte jako rozdíl n-tých složek požadovaného a skutečného výstupu, násobený derivací přechodové funkce z potenciálu tohoto neuronu. f' tedy značí derivaci přechodové funkce neuronu, na němž počítáme deltu.
1.3 Postupně pro nižší vrstvy k
1.3.1
![]() +=
+=![]()
V poli weightDeltas se postupně přes jednotlivé vstupy nasčítávají korekce vah. Výraz výše tedy počítá korekci, která se přičte k váze mezi j-tým neuronem (k+1)-ní vrstvy a i-tým neuronem k-té vrstvy. Jedná se o součin delty neuronu z vyšší vrstvy a výstupu neuronu z nižší vrstvy.
1.3.2
![]() +=
+=![]()
Podobně jako se ve weightDeltas nasčítává korekce vah, v biasDeltas se nasčítává korekce pro prahy.
1.3.3
![]()
Nyní počítáme deltu na neuronu (nikoli na váze). Delta na i-tém neuronu k-té vrstvy (označíme ho n) se spočte jako suma všech delt neuronů z následující vrstvy, násobených hodnotami vah, které je spojují s neuronem n, to celé ještě násobené derivací přechodové funkce na neuronu n.
2.
![]() +=
+=![]()
Váhy upravíme podle weightDeltas. Odpovídající složky jsou nejprve vynásobeny faktorem alpha/numVectors a pak přičteny k odpovídajícím vahám. numVectors značí počet vstupních vektorů. alpha se nazývá parametr učení a jeho hodnota může významně ovlivnit rychlost a efektivitu učení.
3.
![]() +=
+=![]()
Podobně jako váhy se upraví i prahy.
5.![]()
Chyba se spočítá jako součet přes všechny dvojice vstupů a požadovaných výstupů, jako součet rozdílů odpovídajících složek, umocněných na druhou, a celé se ještě dělí dvěma.
4. Pokud bylo dosaženo zadaného počtu kroků, nebo pokud hodnota chyby klesla pod hodnotu errorThreshold, skonči.
Jinak pokračuj od bodu 1.
K učení Backpropagation sítě se používá algoritmus, který je potomkem třídy BPLearning, tedy například připravený algoritmus MyBPLearning. Dále jsou pro učení potřeba data - vstupy a požadované výstupy. Vstupem sítě s n vstupními neurony je buďto vektor délky n nebo více takových vektorů, přesněji řečeno matice o rozměrech m*n. Obdobně požadované výstupy musí mít rozměry odpovídající počtu výstupních neuronů sítě, a opět to může být buď jeden vektor nebo celá matice. Pro učení je nutné mít stejný počet vstupů jako požadovaných výstupů, tj. buď vektor a vektor nebo dvě matice, jejichž první rozměry jsou stejné.
Tedy například pro síť, která má 3 vstupní neurony a 2 výstupní, by byla vhodná učící data třeba matice 6*3 coby vstup a matice 6*2 coby požadovaný výstup.
Po
kliknutí na
![]() se
nejprve objeví dialog, ve kterém se zadávají učící data. Automaticky
se vybírá pouze z dat kompatibilních se sítí.
se
nejprve objeví dialog, ve kterém se zadávají učící data. Automaticky
se vybírá pouze z dat kompatibilních se sítí.

Pokud jsou data nekompatibilní navzájem, po stisknutí OK se objeví chybové hlášení „Incompatible Input and Desired Output Dimensions“. Pokud jsou data v pořádku, otevřou se dvě nové záložky:
Ovládací panel učícího algoritmu.

V horní části je zobrazen název vybraného algoritmu, pod ním informace o provádění:
numSteps
celkový počet předložení celé testovací množiny, neboli celkový počet kroků algoritmu,
lze během učení upravovat;
macroStep
určuje,
kolik kroků algoritmu se bude provádět v módu MACRO při
stisku tlačítka
![]() ,
,
lze během učení upravovat;
curStep
aktuální krok algoritmu,
read-only;
stepMode
mód krokování
algoritmu, ovlivňuje chování tlačítka
![]() ,
,
lze během učení upravovat
MICRO -
při stisku
![]() se
síti předloží jeden vektor,
se
síti předloží jeden vektor,
NORMAL -
při stisku
![]() se
síti předloží celá učící množina,
se
síti předloží celá učící množina,
MACRO
- při stisku
![]() se
síti předloží celá učící množina, a to vícekrát podle macroStep;
se
síti předloží celá učící množina, a to vícekrát podle macroStep;
priority
určuje prioritu vlákna, ve kterém běží učící algoritmus,
lze během učení upravovat,
MIN_PRIORITY - nízká priorita,
NORM_PRIORITY - střední priorita,
MAX_PRIORITY - vysoká priorita.
V dolní části je umístěna nástrojová lišta s ovládacími tlačítky pro učící algoritmus:
![]() /
/
![]() -
spuštění učícího algoritmu, je-li spuštěn, pak jeho pozastavení,
-
spuštění učícího algoritmu, je-li spuštěn, pak jeho pozastavení,
![]() -
krokování učícího algoritmu, konkrétní chování závisí na nastavení
stepMode,
-
krokování učícího algoritmu, konkrétní chování závisí na nastavení
stepMode,
![]() -
zastavení učícího algoritmu.
-
zastavení učícího algoritmu.
V ovládacím panelu algoritmu je kromě spouštění, zastavování, krokování a udávání velikosti kroku možné měnit parametry algoritmu, má-li nějaké - v případě MyBPLearning parametr alpha (viz popis učícího algoritmu) a error_threshold, který udává hodnotu chyby, při jejímž dosažení algoritmus končí.
Panel s učícími daty: obsahuje tabulku se vstupy, požadovanými výstupy, skutečnými výstupy a hodnotou chyby. Jeden řádek vždy obsahuje jeden vstupní vektor a jemu odpovídající výstup, požadovaný výstup a chybu. Jak učení postupuje, aktualizují se hodnoty v tabulce. Aktuální řádek je v tabulce označen zeleně.
Testování znamená předkládání vstupů síti a případně porovnávání skutečných výstupů sítě s požadovanými.
Testování
se spouští kliknutím na tlačítko
![]() .
Objeví se dialog pro testování, ve kterém je možné vybrat testovací
data, jež se, stejně jako u učení, vybírají jen z dat kompatibilních
s aktuální sítí:
.
Objeví se dialog pro testování, ve kterém je možné vybrat testovací
data, jež se, stejně jako u učení, vybírají jen z dat kompatibilních
s aktuální sítí:

Input - vstupy sítě, je nutné je zadat (bez nich by nemělo testování smysl);
Desired Output - požadované výstupy sítě, není nutné zadávat, lze testovat i bez nich (v tabulce pak budou jen vstupy a jim odpovídající výstupy).
Po
stisknutí tlačítka OK v dialogu pro testování se objeví nový
panel:
panel s testovacími daty.

Panel
s testovacími daty obsahuje tabulku, která má stejný význam jako
tabulka s učícími daty při učení. Obsahuje vstupy (input), požadované
výstupy (byly-li zadány, desired), skutečné výstupy (output) a
hodnotu chyby (byly-li zadány požadované výstupy, error). Jeden řádek
vždy obsahuje jeden vstupní vektor a jemu odpovídající výstup,
požadovaný výstup a chybu. Aktuální řádek je v tabulce označen
zeleně.
Na panelu s testovacími daty jsou navíc k dispozici ovládací tlačítka:
![]() předloží
síti jeden testovací vzor, tj. jeden řádek tabulky s testovacími
daty;
předloží
síti jeden testovací vzor, tj. jeden řádek tabulky s testovacími
daty;
![]() předloží
síti celou testovací množinu, tj. postupně všechny řádky tabulky
s testovacími daty;
předloží
síti celou testovací množinu, tj. postupně všechny řádky tabulky
s testovacími daty;
![]() slouží
k uložení sloupců s výstupy do datové proměnné (matice nebo
vektoru).
slouží
k uložení sloupců s výstupy do datové proměnné (matice nebo
vektoru).
Kohonenovy mapy neboli samoorganizující se mapy (Self-Organizing Maps, SOM) patří mezi sítě s učením bez učitele. To znamená, že pro své nastavení nepotřebují znát ideální cílové vzory, jejichž získání může být problémem. Síť sama ve vstupních datech nalezne společné znaky nebo odlišnosti, sama se rozhodne, která odezva je pro daný vzor nejlepší, a podle toho nastaví své váhy. K učení tak stačí jen dostatečně velká skupina vstupních vzorů.
Možné aplikace zahrnují:
vizualizaci vícedimenzionálních dat,
automatické třídění,
hledání podobností v neznámých datech,
zpracování řeči,
analýzu fotografií
a mnoho dalších.
Kohonenova mapa se skládá ze vstupních a výstupních neuronů. Výstupní neurony tvoří dvourozměrnou mřížku, v našem případě šestiúhelníkovou, každý výstupní neuron zná své sousedy v mřížce. Vstupní neurony jsou uspořádány do vektoru. Každý vstupní neuron je spojen se všemi výstupními neurony pomocí synapsí, tedy naopak každý výstupní neuron je spojen se všemi vstupními. K jednotlivým synapsím jsou přiřazeny váhy - na váhy se většinou odkazuje pomocí neuronů, ke kterým synapse náleží.
Vyvolání dialogu New net je možné 3 způsoby:
tlačítko
![]() v
panelu sítí nebo
v
panelu sítí nebo
menu Network -> Create network... nebo
kliknutí pravým tlačítkem myši v panelu sítí vyvolá kontextové menu -> Create network...

Dialog New net:
Name - uživatelské jméno sítě,
Model - zde je možné zvolit model sítě, tedy nyní Kohonen net,
Number of Input Neurons - počet vstupních neuronů,
Height of Output Neurons Grid - výška mřížky výstupních neuronů (v počtu neuronů),
Width of Output Neurons Grid - šířka mřížky výstupních neuronů (v počtu neuronů).
Počet výstupních neuronů je tedy dán jako součin výšky a šířky mřížky výstupních neuronů. Nakonec stisknout tlačítko OK.
Panel Kohonenovy mapy slouží k vizualizaci a práci s jednou konkrétní Kohonenovou mapou. Je vyvolán dvojklikem na jméno sítě v manažeru sítí.
Poznámka: Situace je trochu složitější při práci s verzemi - viz 7.7 Verzování.
Poznámka: Pokud je při dvojkliku na jméno sítě v manažeru sítí držena klávesa Shift, otevře se síť v editoru dat, který umožňuje procházet datové struktury, jež ji tvoří.

V levé části panelu se nachází 3D vizualizátor, kterým je možno síť prohlížet a kliknutím levým tlačítkem myši vybírat jednotlivé neurony. Vybraný neuron je znázorněn pomocí žlutého kuželu, který kolem něho krouží. Vizualizátor zobrazuje výstupní neurony v mřížce a pod nimi vektor vstupních neuronů, pro přehlednost jsou vynechány synapse mezi neurony.
Ovládání 3D vizualizátoru:
pohyb myší se stisknutým levým tlačítkem sítí otáčí,
pohyb myší se stisknutým pravým tlačítkem síť posouvá,
pohyb myší nahoru/dolu se stisknutým kolečkem (prostředním tlačítkem) síť oddaluje/přibližuje,
dvojklik levým tlačítkem nastaví iniciální zobrazení a polohu sítě.
V pravé části panelu jsou informace o právě vybraném neuronu:
není-li vybraný žádný neuron, zobrazuje nápis null;
je-li vybraný vstupní neuron, zobrazuje
jeho index ve vektoru vstupních neuronů (index),
odkaz na jeho váhový vektor, tj. váhy na synapsích mezi vybraným neuronem a všemi výstupními neurony (weights),
jeho aktuální vstup při učení nebo testování (input);
je-li vybraný výstupní neuron, zobrazuje
jeho index, pokud by byly výstupní neurony uspořádány do vektoru (index),
číslo řádky, kde se nachází v mřížce výstupních neuronů (row),
číslo sloupce, kde se nachází v mřížce výstupních neuronů (col),
odkaz na jeho váhový vektor, tj. váhy na synapsích mezi vybraným neuronem a všemi vstupními neurony (weights),
odkaz na jeho sousedy v mřížce (neighbours).
Všechna číslováni (index, row, col) začínají od nuly.
Poslední částí panelu, nacházejícím se vpravo dole, je nástrojová lišta, která obsahuje tlačítka pro práci se sítí:
![]() ...
učení sítě,
...
učení sítě,
![]() ...
testování sítě,
...
testování sítě,
![]() ...
reinicializace všech vah,
...
reinicializace všech vah,
![]() ...
klastrování.
...
klastrování.
Pro učení Kohonenovy mapy je třeba:
mít otevřenou Kohonenovu mapu (panel Kohonenovy mapy),
mít učící data (datovou proměnnou), tj. vektor, resp. matici, jehož délka, resp. její šířka, odpovídá počtu vstupních neuronů,
mít učící algoritmus pro Kohonenovy mapy (tj. potomka třídy KohonenLearning), v aplikaci je zabudovaný takový algoritmus MyKohonenLearning.
V panelu Kohonenovy mapy stačí kliknout na tlačítko
![]() ,
objeví se dialog pro učení, ve kterém je možné vybrat konkrétní
učící algoritmus a učící data:
,
objeví se dialog pro učení, ve kterém je možné vybrat konkrétní
učící algoritmus a učící data:

Algorithm - učící algoritmus, v seznamu jsou k dispozici jen učící algoritmy pro Kohonenovu mapu,
Input - učící data, v seznamu jsou k dispozici jen ty datové proměnné, které mají správné rozměry.
Po
stisknutí tlačítka OK v dialogu pro učení se objeví nové
panely:
panel s učícími daty,
ovládací panel učícího algoritmu,
panel s výstupy v oblasti Output.

Panel s učícími daty obsahuje tabulku, ve které jsou data, jež byla zvolena v dialogu pro učení, obohacenou o jeden (poslední) sloupec. V tomto sloupci se postupně, jak jsou síti předkládány jednotlivé vstupní vektory, objevuje index vítězného neuronu pro tento vstup. Aktuálně předkládaný vstupní vektor je v tabulce označen zeleně; současně jsou podle jeho hodnot ve vizualizátoru sítě v panelu Kohonenovy mapy obarveny vstupní neurony (modrá barva odpovídá minimální hodnotě, červená barva odpovídá maximální hodnotě, odstíny z přechodu od modré k červené odpovídají ostatním hodnotám).
Ovládací panel učícího algoritmu slouží k zobrazení informací o provádění a ovládáni učícího algoritmu. V horní části je zobrazen název vybraného algoritmu, pod ním informace o provádění:
numSteps
celkový počet kroků algoritmu,
krokem algoritmu se rozumí předložení celé testovací množiny,
lze během učení upravovat;
macroStep
určuje,
kolik kroků algoritmu se bude provádět v módu MACRO při stisku
tlačítka
![]() ,
,
lze během učení upravovat;
curStep
aktuální krok algoritmu,
read-only;
stepMode
mód krokování
algoritmu, ovlivňuje chování tlačítka
![]() ,
,
lze během učení upravovat,
MICRO - při
stisku
![]() se
síti předloží jeden vektor z učící množiny,
se
síti předloží jeden vektor z učící množiny,
NORMAL - při
stisku
![]() se
síti předloží celá učící množina (1 krok),
se
síti předloží celá učící množina (1 krok),
MACRO
- při stisku
![]() se
síti předloží celá učící množina, a to vícekrát podle macroStep;
se
síti předloží celá učící množina, a to vícekrát podle macroStep;
priority
určuje prioritu vlákna, ve kterém běží učící algoritmus,
lze během učení upravovat,
MIN_PRIORITY - nízká priorita,
NORM_PRIORITY - střední priorita,
MAX_PRIORITY - vysoká priorita.
V dolní části je umístěna nástrojová lišta s ovládacími tlačítky pro učící algoritmus:
![]() /
/
![]() -
spuštění učícího algoritmu, je-li spuštěn, pak jeho pozastavení,
-
spuštění učícího algoritmu, je-li spuštěn, pak jeho pozastavení,
![]() -
krokování učícího algoritmu, konkrétní chování závisí na nastavení
stepMode,
-
krokování učícího algoritmu, konkrétní chování závisí na nastavení
stepMode,
![]() -
zastavení učícího algoritmu.
-
zastavení učícího algoritmu.
Algoritmus MyKohonenLearning je vestavěný učící algoritmus pro učení Kohonenovy mapy.
Síti jsou postupně předkládány jednotlivé vstupní vzory, podle kterých se neuronům upravují váhy. Mřížka, na níž jsou uspořádané výstupní neurony, umožňuje identifikaci nejbližších sousedů daného neuronu - v průběhu učení se tak aktualizují váhy příslušných neuronů i jejich sousedů. Cílem tedy je, aby sousední neurony také reagovaly na velmi podobné signály.
Zvol hodnoty vah mezi n vstupními a m výstupními neurony jako malé náhodné hodnoty. Zvol poloměr okolí a vzdálenostní koeficient phi.
Nově
vytvořená síť má takto inicializované váhy, případně je možné provést
novou inicializaci pomocí tlačítka
![]() na
panelu Kohonenovy mapy.
na
panelu Kohonenovy mapy.
Poloměr okolí je zvolen 2 - neuronům do vzdálenosti 2 od vítěze (viz níže) budou aktualizovány váhy.
To, jak jsou vzdálenějším neuronům aktualizovány váhy, ovlivňuje vzdálenostní koeficient phi. Jeho hodnota klesá s rostoucí vzdáleností od vítěze, v MyKohonenLearning zvolen: 1.5*(1 / (vzdálenost+1)).
Předlož nový trénovací vzor.
Spočítej
vzdálenosti dj mezi vstupním a váhovým
vektorem pro každý výstupní neuron j pomocí:
kde
xi(t) je vstupem neuronu i v
čase t
a wij(t) je váhou synapse ze vstupního
neuronu i do výstupního neuronu j v čase t.
Pro každý výstupní neuron se spočítá vzdálenost ke vstupnímu vektoru (trénovacímu vzoru).
Vyber takový výstupní neuron c, který má minimální dj a označ ho jako "vítěze".
Váhy
se aktualizují pro neuron c a všechny neurony v okolí. Nové
váhy jsou:![]()
pro
j z okolí.
Hodnota funkce phi(c,j) klesá s rostoucí
vzdáleností od vítěze;
alpha(t) je bdělostní koeficient (0
< alpha(t) < 1), který klesá v čase.
Při
procesu učení tak vítězný neuron upraví svůj váhový vektor směrem k
aktuálnímu vstupnímu vektoru. Totéž platí pro neuron v okolí vítěze.
K váhovému vektoru výstupního neuronu se přičte upravený rozdíl od vstupního vektoru. „Úprava“ závisí na vzdálenosti daného výstupního neuronu od vítěze (phi) a na kroku algoritmu (alpha).
alpha je v MyKohonenLearning: 0.1 * (1 - t / 2000.0).
Přejdi ke kroku 2.
Pro testování Kohonenovy mapy je třeba:
mít otevřenou Kohonenovu mapu (panel Kohonenovy mapy),
mít testovací data (datovou proměnnou), tj. vektor, resp. matici, jehož délka, resp. její šířka, odpovídá počtu vstupních neuronů.
V panelu Kohonenovy mapy stačí kliknout na tlačítko
![]() ,
objeví se dialog pro testování, ve kterém je možné vybrat
testovací data:
,
objeví se dialog pro testování, ve kterém je možné vybrat
testovací data:

Input - testovací data, v seznamu jsou k dispozici jen ty datové proměnné, které mají správné rozměry.
Po
stisknutí tlačítka OK v dialogu pro testování se objeví nový
panel:
panel s testovacími daty.

Panel s testovacími daty, obdobně jako panel s učícími daty při učení sítě, obsahuje tabulku, ve které jsou data, jež byla zvolena v dialogu pro testování, obohacenou o jeden (poslední) sloupec. V tomto sloupci se postupně, jak jsou síti předkládány jednotlivé vstupní vektory, objevuje index vítězného neuronu pro tento vstup. Aktuálně předkládaný vstupní vektor je v tabulce označen zeleně; současně jsou podle jeho hodnot ve vizualizátoru sítě v panelu Kohonenovy mapy obarveny vstupní neurony (modrá barva odpovídá minimální hodnotě, červená barva odpovídá maximální hodnotě, odstíny z přechodu od modré k červené odpovídají ostatním hodnotám).
Na panelu s testovacími daty jsou navíc k dispozici ovládací tlačítka:
![]() předloží
síti jeden testovací vzor, tj. jeden řádek tabulky s testovacími
daty;
předloží
síti jeden testovací vzor, tj. jeden řádek tabulky s testovacími
daty;
![]() předloží
síti celou testovací množinu, tj. postupně všechny řádky tabulky
s testovacími daty;
předloží
síti celou testovací množinu, tj. postupně všechny řádky tabulky
s testovacími daty;
![]() slouží
k uložení tabulky s testovacími daty včetně sloupce s vítězi do
datové proměnné.
slouží
k uložení tabulky s testovacími daty včetně sloupce s vítězi do
datové proměnné.
Při
práci s Kohonenovou mapou je kdykoliv možné reinicializovat váhovou
matici, tedy váhy na synapsích mezi vstupními a výstupními neurony.
Slouží k tomu tlačítko
![]() na
panelu Kohonenovy mapy. Po stisku
na
panelu Kohonenovy mapy. Po stisku
![]() a
potvrzení akce se váhová matice vyplní pseudonáhodnými čísly typu
double z intervalu <0,1).
a
potvrzení akce se váhová matice vyplní pseudonáhodnými čísly typu
double z intervalu <0,1).
Klastrování je technika statistické analýzy dat. Jedná se o rozdělení objektů do skupin (shluků, klastrů) tak, aby si objekty ve stejné skupině byly podobnější než objekty z různých skupin. V případě Kohonenových map je cílem rozdělit do skupin výstupní neurony, za míru pro posouzení jejich blízkosti nebo vzdálenosti se bere Eukleidovská vzdálenost váhových vektorů.
Pro klastrování Kohonenovy mapy je třeba:
mít otevřenou Kohonenovu mapu (panel Kohonenovy mapy).
V
panelu Kohonenovy mapy stačí kliknout na tlačítko
![]() .
Objeví se nové panely:
.
Objeví se nové panely:
panel klastrování,
panel s výstupy v oblasti Output.

Panel klastrování obsahuje ve své levé části vizualizaci a v pravé části ovládací prvky.
Klastrování je vizualizováno pomocí šestiúhelníkové sítě - červené body označují výstupní neurony a červené úsečky ukazují hranice mezi klastry. Šestiúhelníky bez červené tečky nesou informaci o vzdálenosti výstupních neuronů, s jejichž šestiúhelníky (tj. šestiúhelníky, ve kterých tyto neurony leží) sousedí. Vzdáleností se rozumí Eukleidovská vzdálenost váhových vektorů. Jednotlivé šestiúhelníky mají barvy od bílé k černé; bílá znamená nejmenší vzdálenost, černá znamená největší vzdálenost.
Ovládací prvky klastrování:
Clusters count - počet klastrů, může být 1 až počet výstupních neuronů;
Optimal count - nalezne optimální počet klastrů a vyplní tuto hodnotu do Clusters count;
Show distances - zobrazení vzdáleností, pokud není označeno, jsou všechny šestiúhelníky bílé;
Hexagon size - velikost šestiúhelníků, může být 1 až 500;
Do clustering - provedení klastrování, vykreslí červené hranice klastrů (např. po změně počtu klastrů).
Optimální počet klastrů se určuje ohodnocením všech možných klastrování. Číslo Hexagon size je násobek základní velikosti obalového čtverce šestiúhelníku, která činí 40 bodů.
Panel
s výstupy v oblasti Output poskytuje informace o klastrování v
textové podobě.
--- Moje Kohonenova mapa clustering ---
Clusters count: 4
Cluster #1: 2, 4, 9, 8, 6, 16, 1, 20, 12, 5, 0
Cluster #2: 3, 7
Cluster #3: 17, 13, 21, 18, 14, 10, 22
Cluster #4: 15, 19, 23, 11
Sítě typu Hopfield patří do kategorie tzv. asociativních pamětí. Jejich hlavní funkcí je rozpoznávat po naučení vstupní vzory, a to i v případě, že jsou „mírně zašuměné“. Při podrobnější klasifikaci bychom je pak zařadili mezi autoasociativní sítě se zpětnou vazbou, což znamená, že v každé fázi vybavování vzoru se vypočtený výstup použije jako nový vstup sítě, dokud není dosaženo stabilního stavu.
Síť typu Hopfield s n neurony se skládá z jediné vrstvy, ve které jsou neurony spojeny každý s každým. Neuron je charakterizován svým prahem a váhami spojů s ostatními neurony v síti, celou konfiguraci sítě tedy určuje vektor prahů délky n a čtvercová matice vah typu n*n. Váhy nemohou být zcela libovolné, je požadováno, aby matice vah byla symetrická s nulovou diagonálou.
Jednotlivé neurony se vždy nacházejí ve dvou možných stavech: aktivní a neaktivní, což je informace, kterou kódujeme bipolárně – aktivní neuron má výstupní hodnotu 1 a neaktivní -1. Předložit síti vzor znamená definovat pomocí vektoru délky n složeného z hodnot 1 a -1 stavy aktivity jednotlivých neuronům. Vektoru složeného z výstupních hodnot jednotlivých neuronů v daném okamžiku říkáme současný stav sítě.
Pro usnadnění práce s bipolárními vektory používanými v sítích typu Hopfield pro reprezentaci předkládaných vzorů a současného stavu sítě zavádí program iSNS typ uživatelských proměnných obrázek (Hopfield picture). Navenek se proměnné tohoto typu skutečně prezentují jako černobílý obrázek, který má svou výšku w a šířku h. Uvnitř se ale jedná o jednorozměrný bipolární vektor (délky w*h), který je pouze obohacen o informaci, jak jeho položky rozkládat do jednotlivých políček obdélníkové matice.
Taková reprezentace je z výhodou využívána v případě, že vstupem konkrétní sítě jsou skutečná dvourozměrná obrazová data, např. bitmapy rozpoznávaných znaků při úloze OCR. Pokud se naopak k charakteru řešené úlohy dvourozměrné zobrazení příliš nehodí, je možné jeden z rozměrů obrázku položit roven 1.
Vytvoření sítě typu Hopfield je poměrně jednoduché, stačí pouze zadat šířku a výšku obrázku, který bude používán pro zobrazování současného stavu sítě. Ze součinu šířky a výšky si program sám odvodí počet neuronů vytvářené sítě.
Vyvolání dialogu New net je možné 3 způsoby:
tlačítko
![]() v
panelu sítí nebo
v
panelu sítí nebo
menu Network -> Create network... nebo
kliknutí pravým tlačítkem myši v panelu sítí vyvolá kontextové menu -> Create network...

Dialog New net:
Name - uživatelské jméno sítě,
Model - zde je možné zvolit model sítě, tedy nyní Hopfield net,
Height of neuron grid - výška obrázku používaného pro zobrazení současného stavu sítě,
Width of neuron grid - šířka obrázku používaného pro zobrazení současného stavu sítě.
Panel sítě slouží k vizualizaci jedné konkrétní sítě a k práci s ní. Je vyvolán dvojklikem na jméno sítě v manažeru sítí.
Poznámka: Situace je trochu složitější při práci s verzemi – viz kapitola 7.7 Verzování.
Poznámka: Pokud je při dvojkliku na jméno sítě v manažeru sítí držena klávesa Shift, otevře se síť v editoru dat, který umožňuje procházet datové struktury, jež ji tvoří.

Hlavní plochu panelu pro sítě typu Hopfield zabírá část sloužící k zobrazení současného stavu sítě pomocí obrázku. V nově vytvořené síti jsou stavy aktivity jednotlivých neuronů náhodné, proto ze začátku práce se sítí obrázek v podstatě zobrazuje šum. Později, během učení a vybavování, bude možno v obrázku sledovat změny v síti. Stavy aktivity jde pomocí tohoto náhledu též měnit – kliknutím na určitý pixel obrázku neuron přepne z aktivního stavu do neaktivního a naopak.
Spodní část panelu tvoří nástrojová lišta, která obsahuje tlačítka pro práci se sítí:
![]() ...
reinicializace vah sítě,
...
reinicializace vah sítě,
![]() ...
učení sítě,
...
učení sítě,
![]() ...
analýza sítě (..),
...
analýza sítě (..),
![]() ...
vybavování naučených vzorů,
...
vybavování naučených vzorů,
![]() ...
nastavení současného stavu sítě z uživatelské proměnné,
...
nastavení současného stavu sítě z uživatelské proměnné,
![]() ...
uložení současného stavu sítě do uživatelské proměnné,
...
uložení současného stavu sítě do uživatelské proměnné,
![]() ...
zašumění současného stavu sítě.
...
zašumění současného stavu sítě.
Nově
vytvořená síť v sobě nemá naučený žádný vzor. To znamená, že její
matice vah i vektor prahů jsou nulové. Pomocí funkce reinicializace
vah (stisknutím tlačítka
![]() )
lze dosáhnout stejného stavu – tedy vynulování matice vah a
vektoru prahů – kdykoliv při práci se sítí. Je nutné si
uvědomit, že po takovém zásahu se ztratí informace o všech naučených
vzorech a stojí tedy za zvážení si před reinicializací uložit
verzi sítě kapitola 7.7 Verzování.
)
lze dosáhnout stejného stavu – tedy vynulování matice vah a
vektoru prahů – kdykoliv při práci se sítí. Je nutné si
uvědomit, že po takovém zásahu se ztratí informace o všech naučených
vzorech a stojí tedy za zvážení si před reinicializací uložit
verzi sítě kapitola 7.7 Verzování.
Současný stav sítě – tedy informaci o aktivitě jednotlivých neuronů – lze nastavovat z uživatelských proměnných a též do nich ukládat. Slouží k tomu uživatelské proměnné typu obrázek.
Pro
nastavení současného stavu sítě stačí stisknout tlačítko
![]() a
v dialogovém okně si vybrat, která z proměnných se použije pro
nastavení. Dialog nabízí k výběru pouze takové proměnné typu obrázek
z projektu, které jsou kompatibilní s rozměry sítě.
a
v dialogovém okně si vybrat, která z proměnných se použije pro
nastavení. Dialog nabízí k výběru pouze takové proměnné typu obrázek
z projektu, které jsou kompatibilní s rozměry sítě.

Pro
uložení současného stavu sítě do proměnné se používá tlačítko
![]() .
Po zadání jména pro novou proměnnou dojde k jejímu vytvoření a
naplnění hodnotami aktivity jednotlivých neuronů. Nově vzniklá
proměnná bude typu obrázek s rozměry shodnými s rozměry zadanými při
vzniku současné sítě.
.
Po zadání jména pro novou proměnnou dojde k jejímu vytvoření a
naplnění hodnotami aktivity jednotlivých neuronů. Nově vzniklá
proměnná bude typu obrázek s rozměry shodnými s rozměry zadanými při
vzniku současné sítě.
Při
práci se sítí typu Hopfield nás často zajímá, jak hodně zašuměný
(pozměněný) vzor ještě dokáže síť zrekonstruovat. Pomocí tlačítka
![]() můžeme
takovýto vzor snadno vyrábět. Za každé jeho zmáčknutí náhodně
změní některé neurony sítě stav z aktivního na neaktivní či naopak.
Konkrétně to znamená, že každý neuron má desetiprocentní šanci, že
pro něj bude vygerována nová hodnota aktivity (a neuron pak bude z 50
procent aktivní a z 50 neaktvní).
můžeme
takovýto vzor snadno vyrábět. Za každé jeho zmáčknutí náhodně
změní některé neurony sítě stav z aktivního na neaktivní či naopak.
Konkrétně to znamená, že každý neuron má desetiprocentní šanci, že
pro něj bude vygerována nová hodnota aktivity (a neuron pak bude z 50
procent aktivní a z 50 neaktvní).
Učení
sítě lze vyvolat kliknutím na tlačítko
![]() panelu
sítě. Zobrazen bude následující dialog se seznamem se sítí
kompatibilních proměnných typu obrázek, které je možno použít jako
vzory pro učení.
panelu
sítě. Zobrazen bude následující dialog se seznamem se sítí
kompatibilních proměnných typu obrázek, které je možno použít jako
vzory pro učení.

Ze seznamu lze vybrat jeden nebo více vzorů pro naučení. Pro označení více vzorů je třeba přidržet klávesu Ctrl.
Implementace učení sítí typu Hopfield v programu iSNS je založena na myšlence tzv. Hebbovského učení. Tato metoda vychází z následující ideje:
„Dva neurony, které jsou současně aktivní, by měly mít vyšší stupeň vzájemné interakce, než neurony, jejichž aktivita je nekorelovaná – v takovém případě by měla být vzájemná interakce hodně malá nebo nulová.“
V praxi dojde při učení jednoho nového vzoru x k následující aktualizaci matice vah W.

Kde I představuje jednotkovou matici, kterou je nutno odečíst, aby byla zachována podmínka nulové diagonály (vektory ve vzorci jsou chápány jako sloupcové). Je dobré si uvědomit, že při Hebbovském učení se neaktualizuje hodnota vektoru prahů a ty zůstávají stále nulové.
Proces
vybavování se zahajuje stiskem tlačítka
![]() .
Pokud je vše připraveno pro vybavování, objeví se dialog pro výběr
vybavovacího algoritmu (viz následující obrázek). Vždy je k dispozici
vestavěný algoritmus MyRecollection, je ale možno též vyrábět
algoritmy vlastní (více o tvorbě vlastních algoritmů viz kapitola 9
Algoritmy) a nabídku rozšiřovat. V případě, že už vybavování běží
(nebo pokud je spuštěna analýza sítě) není možné další vybavování
spouštět.
.
Pokud je vše připraveno pro vybavování, objeví se dialog pro výběr
vybavovacího algoritmu (viz následující obrázek). Vždy je k dispozici
vestavěný algoritmus MyRecollection, je ale možno též vyrábět
algoritmy vlastní (více o tvorbě vlastních algoritmů viz kapitola 9
Algoritmy) a nabídku rozšiřovat. V případě, že už vybavování běží
(nebo pokud je spuštěna analýza sítě) není možné další vybavování
spouštět.

Po
vybrání požadovaného algoritmu se objeví panel pro vybavování. Lze
pomocí něj vybavování spouštět, zastavovat a krokovat, případně
libovolně měnit jeho parametry. Vše probíhá standardním způsobem
tak jako u ostatních algoritmů.

Obrázek výše ukazuje typický vzhled panelu pro vybavování. V horní části panelu je možno se dozvědět jméno algoritmu, kterým právě vybavujeme, níže pak panel zobrazuje parametry algoritmu. Parametry algoritmu se mohou lišit v závislosti na jeho typu. Vždy jsou ale přítomny tyto parametry:
stepMode, který určuje po jak velkých krocích bude probíhat krokování,
priority, jehož hodnota určuje prioritu vlákna algoritmu v rámci programu.
Poznámka: Parametr priority je pouze pro pokročilé uživatele programu – typicky je přednastavená hodnota ideální a není třeba ji měnit.
V dolní části panelu pro vybavování je umístěna nástrojová lišta s ovládacími tlačítky pro učící algoritmus:
![]() /
/
![]() -
spuštění učícího algoritmu, je-li spuštěn, pak jeho pozastavení,
-
spuštění učícího algoritmu, je-li spuštěn, pak jeho pozastavení,
![]() -
krokování učícího algoritmu, konkrétní chování závisí na nastavení
stepMode,
-
krokování učícího algoritmu, konkrétní chování závisí na nastavení
stepMode,
![]() -
zastavení učícího algoritmu.
-
zastavení učícího algoritmu.
Vestavěný algoritmus pro vybavování v sítích typu Hopfield se jmenuje MyRecollection. Je to algoritmus založený na asynchronní aktualizaci stavu neuronů s podporou pro simulované žíhání.
Při základním nastavení probíhá vybavování následovně. Vždy je náhodně vybrán jeden z neuronů, jehož stav se bude aktualizovat (např. i-tý). Nový stav aktivity vybraného neuronu se pak spočítá podle vzorce

kde W je matice vah, b vektor prahů a sgn je přechodová funkce pro sítě typu Hopfield, která vrací hodnotu 1 pro nezáporné vstupy a -1 jinak. O matici vah se předpokládá, že je symetrická s nulovou diagonálou, z čehož mj. plyne, že nový stav aktivity vybraného neuronu závisí obecně na stavu všech neuronů ostatních, ale nikoliv na předchozím stavu neuronu samotného.
Vybírání a aktualizace stavu neuronů probíhá stále dokola, dokud síť nedosáhne stabilního stavu – tj. takového, kdy už se aktivita neuronů dále nemění (aktualizace pro každý neuron vypočítá jako novou hodnotu jeho stávající). Tohoto konečného stavu dosáhne síť vždy po konečném počtu aktualizací, pokud jsou splněny požadavky kladené na matici vah.
Vybavování u sítí typu Hopfield nemusí sloužit pouze k rekonstrukci zašuměných předem naučených vzorů. Další možností využití je pomoc při řešení optimalizačních úloh. Ke každé konfiguraci sítě lze totiž přiřadit číslo, tzv. energetickou funkci, o které lze dokázat, že v důsledku změn při aktualizaci stavu neuronů během vybavování pouze klesá, nebo se nemění. Energetická funkce je definována jako

Pokud se nám podaří zakódovat do matice vah a vektoru prahů zadání optimalizační úlohy takovým způsobem, aby stav aktivity jednotlivých neuronů kódoval přípustné řešení úlohy a hodnota energie odpovídala kriteriální funkci úlohy, stane se z procesu vybavování proces hledání optimálního řešení.
Při takovémto způsobu využití není důležité, aby byl vybavený vzor co nejpodobnější počátečnímu předloženému vzoru. Je naopak žádoucí, aby vybavování našlo stabilní stav s co možná nejnižší hodnotou energetické funkce (globální minimum). Toho algoritmus MyRecollection dosahuje použitím myšlenky simulovaného žíhání. Při něm se algoritmus snaží zabránit uvíznutí v lokáním minimu energetické funkce dočasným povolením aktualizace stavu sítě i za cenu přechodného zvýšení energetické hladiny. Pravděpodobnost, že k takové aktualizaci dojde, závisí na parametru algoritmu T, který lze interpretovat jako teplotu.
Pozměněný postup při aktualizaci je pak následující. Hodnota aktivity vybraného neuronu se změní vždy, když může aktualizace zmenšit hodnotu energetické funkce E (jako při klasickém vybavování). Pokud by se při aktualizaci naopak hodnota E zvýšila o dE, bude nová hodnota přijata s pravděpodobností

Pro velké hodnoty T bude p přibližně ½ a aktualizace stavu nastane zhruba v polovině těchto případů. Pro T = 0 bude docházet pouze k takovým aktualizacím, kdy se hodnota E sníží. Postupná změna hodnot T od velmi vysokých hodnot směrem k nule odpovídá zahřátí a postupnému ochlazování v procesu žíhání.
energy – pouze pro čtení – hodnota energetické funkce odpovídající aktuálnímu stavu sítě;
traversal – způsob vybírání neuronů pro aktualizaci:
RANDOM – neuron je vybírán úplně náhodně,
PERMUTATION – neurony jsou vybírány z náhodné permutace (tj. nejprve se vždy zkusí aktualizovat v náhodném pořadí všechny neurony, než se znovu může dostat na řadu první vyzkoušený). Pouze v tomto režimu dokáže algoritmus rozpoznat, že už je síť ve stabilním stavu a sám skončit;
t – parametr T teploty pro simulované žíhání (hodnota 0 znamená, že se simulované žíhání neprovádí);
t_delta – algoritmus automaticky přičítá po každém kroku hodnotu t_delta k parametru t – může sloužit k nastavení automatického snižování teploty;
last_prob – pouze pro čtení – naposledy spočtená pravděpodobnost aktualizace neuronu i za cenu zvýšení energetické funkce (viz podkapitola 7.6.8.1.1 Podpora pro simulované žíhání);
stepMode – způsob krokování algoritmu:
MICRO – algoritmus je možno pozastavit po každém aktualizačním kroku,
NORMAL – algoritmus je možno pozastavit jednou za n, kde n je počet neuronů sítě,
MACRO – algoritmus MyRecollection nejde tímto způsobem krokovat.
Při práci se sítí typu Hopfield často vyvstává otázka, které z naučených vzorů si vlastně síť dokáže vybavit. Teorie totiž ukazuje, že kapacita sítě není neomezená. Navíc mohou být vzájemnou „interferencí“ učených vzorů do sítě zavlečeny další stabilní body, které neodpovídají žádnému z naučených vzorů. Pro lepší vhled do sítě a případnou odpověď na takové otázky je v programu iSNS k dispozici panel pro analýzu sítí typu Hopfield.
Panel
pro analýzu vyvoláme pomocí tlačítka
![]() na
panelu sítě. Je nutno mít na paměti, že analýzu nelze spouštět, pokud
právě na síti běží vybavování. Panel pro analýzu vypadá asi takto:
na
panelu sítě. Je nutno mít na paměti, že analýzu nelze spouštět, pokud
právě na síti běží vybavování. Panel pro analýzu vypadá asi takto:
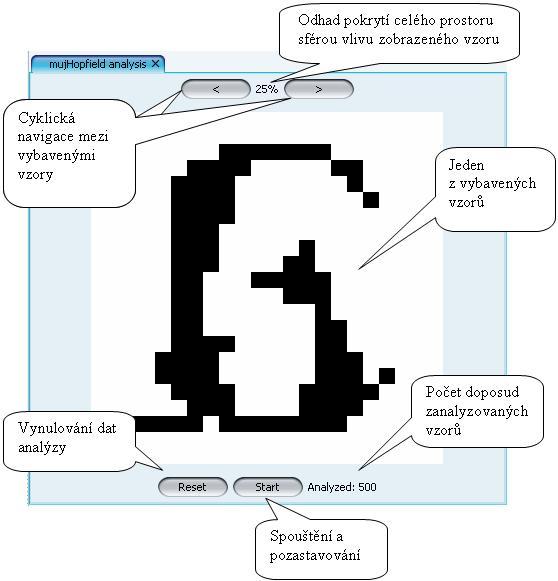
Analýza funguje na statistickém principu. Její algoritmus v každém kroku vygeneruje náhodný vzor, který nastaví jako současný stav sítě. Poté spustí jako podproceduru algoritmus na vybavování tak, aby našla stabilní stav, do kterého síť dokonverguje z onoho náhodného vzoru. Stabilní stav je uložen do záznamů analýzy a v případě, že byl ten samý uložen již v dřívějším kroku, algoritmus si poznamená, že na něj znovu narazil. Takovým postupem algoritmus neustále zpřesňuje odhad pokrytí prostoru všech možných stavů sítě sférami vlivu jednotlivých stabilních bodů.
Poznámka: Jelikož pro každý stabilní bod sítě x platí, že je stabilním bodem i opačný vektor -x, chápou se během analýzy oba tyto vektory jako jeden jediný záznam pro uložení.
Ovládání analýzy je velmi jednoduché: Tlačítka v dolní části panelu slouží ke spuštění / pozastavení analýzy a případnému vynulování získaných výsledků. Střední část panelu zobrazuje jeden z nalezených stabilních bodů. Pomocí tlačítek se šipkami v horní části panelu můžeme cyklicky procházet všechny nalezené stabilní body a textový popisek s procenty mezi tlačítky udává, jak velkou část prostoru všech možných stavů sítě pokrývá sféra vlivu aktuálně zobrazovaného vzoru.
Kromě ukládání proměnné sítě (Save, Save as...) má v programu iSNS uživatel možnost uložit si verzi sítě. Verze nejsou perzistentní (při ukončení práce s programem jsou všechny verze sítě kromě aktuální smazány). Verze mají tu výhodu, že se v manažeru sítí zobrazují ve stromové struktuře a je tudíž snadné poznat, která síť vznikla z které. Uživatel má možnost přidávat si k verzím popisky, které ještě více usnadňují orientaci.

Zvolíme-li v menu Network nebo v kontextovém menu Save version, vznikne verze, ve které bude uložen aktuální stav sítě. Tato verze bude ve stromě verzí umístěna jako potomek aktuální verze a stane se novou aktuální verzí. V každé verzi je uložen stav sítě, jaký byl při vzniku této verze.
Zvolíme-li v menu Network nebo v kontextovém menu Set current version, stane se aktuální verzí označená verze (tzn. vrácení se ke starší verzi). Stejný efekt má dvojklik na verzi, ke které se chceme vrátit.
Přitom se automaticky uloží verze, se kterou jsme do té doby pracovali (pouze v případě, že se liší od naposledy uložené). To znamená, že rozpracovaná verze se při této akci neztratí, ale uloží se, a to jako potomek do té doby aktuální verze. V jejím automaticky vygenerovaném popisku se kromě data objeví poznámka „Before Undo“.
Vizualizační moduly poskytují názornější zobrazení nejen uživatelských dat, ale hlavně interních dat sítí a algoritmů. Mají přístup k jednotlivým položkám sítě a dokáží zobrazovat libovolnou hodnotu, u které sledují vývoj její hodnoty v průběhu učícího algoritmu nebo její změny v závislosti na čase. Některé vizualizační moduly (sloupcový graf BarChart Array, koláčový graf PieChart Array) nesledují vývoj jedné hodnoty, ale jsou určeny pro vizualizaci celého pole dat v jednom okamžiku.
Vytvoření vizualizačního modulu (VM) je možné přes menu Visualization nebo přes kontextové menu oblasti, do které chceme VM přidat jako novou záložku. V menu si lze vybrat ze 13 různých vizualizací:

Po kliknutí na vybranou vizualizaci se otevře okno Select the desired field, ve kterém je potřeba vybrat sledovanou proměnnou.

Kliknutím na + vedle nápisů dataManager/networkManager se zobrazí strom se seznamem podpoložek manažeru dat/sítí. Po stisknutí OK se daný VM vytvoří a přidá se jako nová záložka do hlavní oblasti, případně do oblasti, kde bylo vyvoláno kontextové menu.
Postup je u všech VM stejný s výjimkou zmíněných BarChart Array a PieChart Array vizualizací, kde je potřeba vybrat pole dat. Pro výběr pole je ve stromu dat nutné dvojkliknout na název požadovaného pole, který určí kořen pro další dialog. Nový dialog přesněji specifikuje požadované pole - určuje, které položky v poli chceme sledovat. Pokud se jedná o vektor čísel typu double, je možné kliknout na OK a vizualizace bude sledovat pole čísel. V případě složitějších polí, např. matice, je potřeba vybrat nějakou podpoložku. VM bude poté sledovat pole dat, které tvoří vektor podpoložek ve vybraném poli. Viz příklad vytvoření BarChart Array 3D vizualizace v kapitole 10.3.2 Zobrazení všech výstupů určité vrsty sítě.
Primitivní vizualizační modul zobrazující aktuální hodnotu proměnné číslem. Simple Label je vhodný pro sledování proměnné, u které nemá smysl sledovat historii změn.

Čárový graf, který zobrazuje hodnoty sledované proměnné v závislosti na x-ové ose, tj. typicky krok algoritmu. Klíčové hodnoty jsou v grafu spojené přímou čarou, informace v neklíčových hodnotách tedy neodpovídá skutečné hodnotě proměnné. XY Line Chart je vhodný např. pro sledování průběhu chybové funkce během učení.

Plošný graf, který zobrazuje hodnoty sledované proměnné v závislosti na x-ové ose, tj. typicky krok algoritmu. Klíčové hodnoty jsou v grafu spojené přímou čarou, informace v neklíčových hodnotách tedy neodpovídá skutečné hodnotě proměnné. XY Area Chart je vhodný např. pro sledování průběhu chybové funkce během učení.

Čárový graf, který zobrazuje hodnoty sledované proměnné v závislosti na x-ové ose, tj. typicky krok algoritmu. Průběh grafu je skokový. XY Step Chart je vhodný pro sledování dat, která jsou měněna algoritmem a je potřeba vidět přesnou hodnotu proměnné.
Sloupcový graf. Zobrazuje jednu proměnnou a udržuje historii změn. Vizualizace je implicitně vytvořena pro 20 sloupců v historii, ale za běhu lze pod grafem počet viditelných sloupců libovolně nastavit. Bar Chart je vhodný např. pro sledování vítězných neuronů u Kohonenových map.

3D sloupcový graf. Zobrazuje jednu proměnnou a udržuje historii změn. Vizualizace je implicitně vytvořena pro 20 sloupců v historii, ale za běhu lze pod grafem počet viditelných sloupců libovolně nastavit. Bar Chart 3D je vhodný např. pro sledování vítězných neuronů u Kohonenových map.
Sloupcový graf, který zobrazuje naráz celé pole dat. Bar Chart Array je vhodný např. pro sledování výstupu celé vrstvy neuronů u Backpropagation sítí.

3D sloupcový graf, který vizualizuje naráz celé pole dat. Bar Chart Array 3D je vhodný např. pro sledování výstupu celé vrstvy neuronů u Backpropagation sítí.

Koláčový graf pro sledování současných hodnot jednotlivých prvků pole.

3D koláčový graf pro sledování současných hodnot jednotlivých prvků pole.

Čárový graf, který zobrazuje hodnoty sledované proměnné v závislosti na čase. Klíčové hodnoty jsou v grafu spojené přímou čarou, informace v neklíčových hodnotách tedy neodpovídá skutečné hodnotě proměnné. TimeSeries Line Chart je vhodný pro sledování změn dat, která nejsou měněna algoritmem.

Plošný graf, který zobrazuje hodnoty sledované proměnné v závislosti na čase. Klíčové hodnoty jsou v grafu spojené přímou čarou, informace v neklíčových hodnotách tedy neodpovídá skutečné hodnotě proměnné. TimeSeries Area Chart je vhodný pro sledování změn dat, která nejsou měněna algoritmem.
Čárový graf, který zobrazuje hodnoty sledované proměnné v závislosti na čase. Průběh grafu je skokový v časech, kdy se mění hodnota proměnné. TimeSeries Step Chart je vhodný pro sledování změn dat, která nejsou měněna algoritmem a kdy je potřeba vidět přesné hodnoty proměnné.

S výjimkou jednoduché vizualizace Simple Label mají všechny VM interaktivní ovladání pomocí myši. Podržením levého tlačítka myši a vybráním obdelníkové oblasti grafu lze přiblížit danou oblast a změnit tak rozsah os VM. Oddálení je možné pomocí kontextového menu VM: Zoom Out, popř. Auto Range pro automatické nastavení rozsahu os VM tak, aby byla vidět všechna zobrazovaná data. V obou případech, resp. ve všech 3 případech - menu totiž obsahuje i přiblížení Zoom In, lze zvolit změnu rozsah obou os (Both Axes), popř. jen horizontální (Domain Axis) nebo vertikální osy (Range Axis).
Kontextové menu Properties... otevře nové okno Chart Properties obsahující 3 záložky Title, Plot a Other pro nastavení vzhledu a dalších vlastností grafu:
záložka Title
Show Title - zapíná/vypíná zobrazení nadpisu grafu,
Text - nadpis grafu,
Font - písmo, kterým se zobrazí nadpis grafu,
Color - barva písma pro nadpis grafu;
záložka Plot
sekce General
záložky Domain Axis a Range Axis
Label - popis osy,
Font - písmo, kterým se zobrazí popis osy,
Color - barva písma pro popis osy;
záložka Appearance
Outline stroke - nastavení tloušťky pro okraje grafu,
Outline paint - barva pro okraj grafu,
Background paint - barva pro pozadí grafu,
Orientation - nastavení orientace grafu (horizontální nebo vertikální);
sekce Other
záložka Ticks
Show tick label - zapíná/vypíná zobrazení hodnot podél osy,
Tick label font - písmo, kterým se zobrazí hodnoty,
Show tick marks - zapíná/vypíná zobrazení čar u hodnot podél osy;
záložka Range
Auto-adjust range - zapíná/vypíná automatické přizpůsobení rozsahu os podle dat,
Minimum range value - nastavení minimální zobrazované hodnoty,
Maximum range value - nastavení maximální zobrazované hodnoty;
záložka Other
Draw anti-aliased - zapíná/vypíná vyhlazování,
Background paint - barva okolí grafu.
Některé vizualizační moduly (např. PieChart Array, PieChart Array 3D) neobsahují všechny zmíněné ovládací prvky.
VM podporují pomocí příkazu kontextového menu Save as... uložení grafu na disk jako obrázek ve formátu PNG.
Přes příkaz kontextového menu Print... je možné graf vytisknout.
Odstranění VM se provádí zavřením záložky s vizualizací.
S každým modelem neuronové sítě je typicky spjata určitá výpočetní úloha, jejíž provádění zajišťuje modelu správnou funkci. Klasickým příkladem je úloha učení v případě modelu sítí typu zpětného šíření. Jsou známy mnohé algoritmy jak tyto úlohy řešit a v programu iSNS je pro každou úlohu implementován alespoň jeden takový algoritmus.
Dále je pokročilým uživatelům dána možnost psát algoritmy vlastní a výpočetní možnosti programu tím rozšiřovat. Je k tomu samozřejmě nutná alespoň základní znalost programování, a to v programovacím jazyce Java. V této kapitole, jejímž cílem je osvětlit, jakým způsobem se nové algoritmy v iSNS píší, se proto bude předpokládat, že uživatel je s principy programování v jazyce Java obeznámen.
Pro každou výpočetní úlohu je v programu iSNS připravena abstraktní třída, která definuje základní metody např. pro zajištění přiřazení konkrétního algoritmu danému modelu neuronové sítě, pro signalizování změny stavu sítě vyšším vrstvám programu nebo pro zajištění samotného běhu algoritmu. Součástí jsou dále i datové položky typicky ovlivňující běh algoritmu, např. počet epoch. Implementace algoritmu pro řešení úlohy pak dědí všechny zmíněné metody a datové položky od této třídy, implementuje abstraktní metody a dle potřeby definuje další nové metody a datové položky.
Struktura a význam jednotlivých abstraktních metod uvnitř abstraktní třídy vytyčuje určitý rámec pro implementaci algoritmu dané výpočetní úlohy (tj. určuje možnost využití takového algoritmu, který implementuje tyto abstraktní metody - např. zmíněný algoritmus pro úlohu učení sítě typu zpětného šíření).
Konkrétní popis, tj. popis metod a jejich využití, popis datových struktur apod., je uveden v nápovědě u každého implementovaného algoritmu.
Uživatel, který se rozhodne vytvořit si vlastní algoritmus pro řešení konkrétní výpočetní úlohy, dostane k dispozici třídu, která bude potomkem příslušné abstraktní třídy. V metodách, které by měl uživatel implementovat, bude předvyplněn vzorový kód tak, aby tento algoritmus byl ihned přeložitelný (po jeho uložení do souboru) a použitelný k řešení dané úlohy. Předvyplnění poděděných metod vzorovým kódem umožní uživateli snazší orientaci v samotném kódu metody a navíc pouhou změnou jeho části má uživatel připravenou modifikaci algoritmu, a tedy vlastně algoritmus zcela nový. Samozřejmá je možnost, aby si uživatel napsal kód sám zcela od začátku (stačí vzorový kód smazat).
Před vytvořením nového algoritmu je navíc požadováno zvolení tzv. programátorské úrovně. Ta ve skutečnosti určuje, jaké metody poděděné od abstraktní třídy bude uživatel moci modifikovat. Tzn. určuje, „jak moc“ si bude uživatel moci vytvořit nový algoritmus. Například nejlehčí úroveň NOVICE dovolí uživateli změnit jen málo metod a ostatní použijí kód, který se typicky objevuje u vestavěných algoritmů. Naopak nejtěžší úroveň PROFI nabídne uživateli k modifikaci úplně všechny uživatelsky předefinovatelné metody, takže si tak může napsat algoritmus téměř od základů. Důležité je mít na vědomí, že při vytvoření algoritmu, bude uživatel moci modifikovat metody stejné a nižší programátorské úrovně než tu, kterou si zvolil.
Ale aby uživatel nebyl omezen jen na metody, které nabídne nově vytvořená třída, je v každém algoritmu k dispozici tzv. FREE ZONE. Jde o jakýsi vyhrazený prostor, kam si uživatel může psát své metody a datové struktury. FREE ZONE je ve třídě uživatelského algoritmu uložena přímo do hlavní třídy (algorithm class). Ke zde umístěným metodám a datovým strukturám tak bude možno přistupovat i z metod, které jsou poděděny a jsou tak určeny k modifikaci. FREE ZONE má každý uživatelský algoritmus a zobrazuje se v podstromu algoritmu v manažeru algoritmů.
Ačkoliv není uživateli umožněno vkládat vlastní importy do třídy algoritmu, není tím nijak výrazně omezena možnost vytvářet kód dle své potřeby. Velká část packages je již explicitně importovaná. V případě potřeby je pro přístup ke třídám a metodám daného neimportovaného package nutno použít příslušný prefix.
Příklad
použití package pro práci se soubory pomocí importu:
explicitní import ve třídě algoritmu
import java.math.*;
uživatelský kód
int exp = 35;
BigInteger longNum = 4;
BigInteger out = longNum.pow(exp);
Příklad
použití package pro práci se soubory pomocí prefixu (import
chybí):
uživatelský kód
int exp = 35;
java.math.BigInteger longNum = 4;
java.math.BigInteger out = longNum.pow(exp);
Po úspěšné kopilaci kódu algoritmu (tj. neobsahuje-li kód chyby), dojde automaticky k jeho zaregistrování do programu, čímž bude možno tento algoritmus použít pro práci se sítěmi. Pokud bude algoritmus smazán v manažeru algoritmů, dojde k jeho odregistrování a již ho nebude možné používat.
Pro
správu algoritmů v iSNS se využívají následující ovládací prvky
pracovní plochy:
Manažer algoritmů
zobrazuje hierarchii algoritmů v projektu,
více o ovládání a zobrazovaných skutečnostech v kapitole 4.3 Manažer algoritmů.
Editor algoritmů
je nevizuální komponenta, ale zobrazuje editor metody jako záložku ve zvolené oblasti,
poskytuje prostředky pro vývoj uživatelských algoritmů (viz kapotila 9.5 Editor algoritmů).
Stručný popis tlačítek obou ovládacích prvků (podrobnosti v kapitolách 4.3 Manažer algoritmů a 9.5 Editor algoritmů):
![]() ...
vytvoří nový algoritmus,
...
vytvoří nový algoritmus,
![]() ...
otevře existující algoritmus,
...
otevře existující algoritmus,
![]() ...
uloží algoritmus,
...
uloží algoritmus,
![]() ...
zkompiluje algoritmus,
...
zkompiluje algoritmus,
![]() ...
odstraní algoritmus z projektu,
...
odstraní algoritmus z projektu,
![]() ...
undo pro editaci kódu (jedna změna zpět),
...
undo pro editaci kódu (jedna změna zpět),
![]() ...
redo pro editaci kódu (jedna změna vpřed),
...
redo pro editaci kódu (jedna změna vpřed),
![]() ...
vloží vzorový kód zvolené metody algoritmu,
...
vloží vzorový kód zvolené metody algoritmu,
![]() ...
zobrazí informace o zvolené metodě,
...
zobrazí informace o zvolené metodě,
![]() ...
zobrazí pravidla pro psaní kódu.
...
zobrazí pravidla pro psaní kódu.
Možnosti:
Menu -> Algorithm -> Create algorithm...,
Manažer algoritmů
-> tlačítko
![]() ,
,
Manažer algoritmů -> Kontextové Menu -> Create algorithm...
Na
žádost o vytvoření nového algoritmu (viz možnosti výše) se zobrazí
dialog, ve kterém je potřeba zvolit požadované parametry nového
uživatelského algoritmu. Bude se vybírat třída algoritmu a pak
programátorská úroveň.
Dialog pro vytvoření nového algoritmu

Třída algoritmu: Třída algoritmu představuje základní typ algoritmu odpovídající úloze, kterou má algoritmus řešit. V projektu jsou implicitně vestavěny 4 třídy algoritmů (vestavěné algoritmy), které jsou zobrazeny v první vrstvě stromu vestavěných algoritmů. Každou takovou třídu reprezentuje v programu abstraktní třída (abstract class).
První tři třídy odpovídají základním úlohám tří modelů sítí implementovaných v iSNS: Lze si vybrat učící algoritmy pro sítě typu Backpropagation (tj. BPLearning), Kohonen (tj. KohonenLearning) a vybavovací algoritmus pro síť typu Hopfield (tj. Recollection).
Čtvrtá třída stojí trochu stranou: Je to třída pro přechodovou funkci (tj. TransferFunction), která slouží v sítích typu Backpropagation pro změnu přenášených hodnot mezi neurony.
Pro různé třídy algoritmů je v projektu připraven různý počet vestavěných algoritmů (vždy alespoň jeden). Proto se po označení (po dvojkliku) zvolené třídy rozbalí podstrom vestavěných algoritmů (pokud není rozbalen automaticky). Každý vestavěný algoritmus je reprezentován třídou (class), jejímž předkem je příslušná abstraktní třída.
Uživatel může vytvořit nový algoritmus buď jako potomka abstraktní třídy (tj. třída algoritmů v první vrstvě stromu) nebo jako potomka vestavěného algoritmu (druhá a popřípadě i další vrstva tohoto stromu). Mechanismus vytvoření nového algoritmu je v obou případech stejný (viz popis v úvodu kapitoly Algoritmy).
Ještě je potřeba uvést, že první tři třídy algoritmů (tj. BPLearning, KohonenLearning a Recollection) jsou potomky třídy Algorithm. Ta obsahuje základní prostředky k zajištění podpory pro to, aby všechny takové algoritmy běžely v samostatném vláknu, aby je bylo možné krokovat a zastavit. Dále se též stará o překreslení grafického zobrazení sítě dle aktuálních hodnot, pokud při běhu algoritmu dojde k jejím změnám. O zajištění těchto vlastností se uživatel nemusí téměř starat, protože potřebné metody jsou implementovány přímo v abstraktních třídách (tj. třídách algoritmů v první vrstvě stromu), které jsou vždy (přímými nebo nepřímými) předky každého uživatelského algoritmu. Dále je vhodné podívat se do kapitoly 9.7 Několik doporučení pro psaní uživatelských algoritmů, kde lze nalézt některá upřesnění spolu s návody, jak definovat místa v uživatelském algoritmu pro jeho krokování, jak přidat proměnné, které se zobrazí v panelu učení apod.
Programátorská úroveň: Programátorská úroveň určuje množinu metod, které bude uživatel mít možnost ve svém novém algoritmu předefinovat (popř. implementovat, pokud jeho algoritmus je odvozen od abstraktní třídy, tj. třída algoritmu je jeho přímým předkem, místo od vestavěného algoritmu). Obecně platí, že čím vyšší úroveň, tím je více prostoru pro změnu algoritmu. Na druhou stranu je ale „vetší manipulační prostor“ vyvážen ztrátou podpory - uživatel si musí více věcí naprogramovat sám.
NOVICE: Nejlehčí úroveň. Uživateli stačí naprogramovat velmi málo jednoduchých metod a nestará se o jejich vzájemné volání v kódu.
NORMAL: Střední obtížnost, navíc umožňuje napsat si kód nadřazených metod (tj. i metod, které zajišťují volání NOVICE-metod) a ovlivnit tak částečně další výpočty se sítí.
PROFI: Nejobtížnější úroveň. Pokud je uživatelský algoritmus vytvořen od abstraktní třídy (což není vždy možné), dostane uživatel typicky jen jedinou metodu, kterou musí implementovat. Tato metoda pak musí zajistit odpovídající výpočty a změnu dat sítě. V opačném případě, tj. je-li algoritmus vytvořen od vestavěného algoritmu, je uživateli nabídnuta možnost předefinovat si všechny metody (tj. i NOVICE a NORMAL metody) - součástí je i metoda (říkejme jí hlavní metoda algoritmu) z abstraktní třídy, která již má ve vestavěném algoritmu svou implementaci.
Programátorskou
úroveň lze vybrat až po výběru třídy algoritmu, protože ne ke každé
třídě (popř. vestavěnému algoritmu) jsou k dispozici všechny úrovně.
Při změně výběru třídy nebo vestavěného algoritmu ve stromu
vestavěných algoritmů proto dojde k úpravě možnosti vybrat si
programátorské úrovně. Přesný význam jednotlivých úrovní a jim
odpovídajících metod závisí na modelu resp. úloze, pro kterou je
algoritmus určen. U každé metody je v editoru metody dostupná
informace o jejím významu a použití - více v kapitole 9.5 Editor algoritmů.
Více o konkrétních datových strukturách a metodách předka je uvedeno v nápovědě, která se zobrazuje v záložkách dialogu pro vytvoření nového algoritmu a mění se podle toho, jaká třída algoritmu (popř. jaký vestavěný algoritmus) je zvolen. Pokud je zvolena třída, pak se zobrazují informace o této třídě. Je-li vybrán vestavěný algoritmus, zobrazí se v každé záložce příslušný popis tohoto algoritmu následovaný odpovídajícím popisem třídy. Záložky zobrazují následující informace:
Celkový souhrnný popis třídy.
Popis metod této třídy.
Popis datových struktur, které lze využít při psaní algoritmu.
Po stisku tlačítka OK se v projektu vytvoří nový algoritmus (tj. objeví se ve stromu algoritmů manažeru algoritmů v podstromu příslušné třídy algoritmů) pod implicitním jménem (implicitní jméno je: _new_ + pořadové číslo) a nebude uložený v žádném zdrojovém souboru. Bude potomkem algoritmu, který byl označen ve stromu vestavěných algoritmů s příslušnou programátorskou úrovní.
Všechny metody v novém uživatelském algoritmu budou mít již předem vyplněný vzorový kód, který zhruba odpovídá kódu vestavěných algoritmů a je tedy možné ho bezchybně zkompilovat. Hlavní metoda algoritmu je volána v každém kroku tohoto algoritmu, tj. představuje pro uživatele vstupní bod do jeho části kódu.
Možnosti:
Menu -> Algorithm -> Load algorithm...,
Manažer algoritmů
-> tlačítko
![]() ,
,
Manažer algoritmu -> Kontextové menu -> Load algorithm...
Požadavky:
Algoritmus musí být uložen v zdrojovém java-souboru.
Postup otevření algoritmu:
Vyvoláním požadavku na otevření algoritmu (viz možnosti výše) se otevře dialog, kde se vybere zdrojový soubor s algoritmem, který bude otevřen.
Otevřít lze pouze soubory s příponou .java (zdrojový java-soubor), které vznikly v tomto projektu (tj. mají příslušný formát). Při pokusu otevřít jiné java-soubory se objeví chybové hlášení o nekompatibilitě souboru.
Po potvrzení dialogu se zvolený algoritmus stane součástí projektu, tj. zobrazí se ve stromu algoritmů v manažeru algoritmů.
Pokud se otevře algoritmus s implicitním jménem (tj. _new_xxx), pak ho bude nutné uložit, neodpovídá mu totiž žádný zdrojový soubor - o tom navíc informuje dialog, který se v takovém případě otevře.
Poznámka: Soubor obecně pod implicitním jménem uložit nelze. Dojde k tomu pouze v případě, že se ukládá celý aktuální projekt. Tím se zajistí, že s projektem se uloží i algoritmy (s implicitními jmény), které ještě nebyly uloženy do zdrojových java-souborů. Ty lze pak otevřít, ale opět jakoby nejsou uložené z pohledu aktuálního projektu. Více v následující kapitole 9.3 Uložení algoritmu.
Poté lze otevírat a editovat jednotlivé metody algoritmu - viz kapitola 9.5 Editor algoritmů.
Možnosti:
Menu -> Algorithm -> Save algorithm,
Menu -> Algorithm -> Save algorithm as...,
Manažer algoritmů
-> tlačítko
![]() ,
,
Manažer algoritmů -> Kontextové menu -> Save algorithm,
Manažer algoritmů -> Kontextové menu -> Save algorithm as...
Algoritmus
lze uložit dvěma způsoby - buď pod stejným jménem (Save) nebo
pod novým jménem (Save as). Pokud se ukládá nově vytvořený
algoritmus, tj. takový, který ještě nebyl nikdy uložen, pak mají oba
způsoby stejný průběh i výsledek.
Uložení nově vytvořeného algoritmu (Save i Save as): Zobrazí se dialog, ve kterém si uživatel zvolí adresář, kam se uloží výsledný zdrojový soubor, a dále zvolí jméno algoritmu (s nebo bez přípony „.java“). Poté proběhne samotné uložení algoritmu včetně změn, které provedl při editaci kódu metod od doby vytvoření algoritmu. Podle zadaného jména se změní jméno algoritmu ve stromu algoritmů v manažeru algoritmů a jména záložek otevřených metod tohoto algoritmu. Vždy se uloží kód všech editovaných metod. Pokud nějaká metoda nebyla vůbec editovaná (od doby vytvoření algoritmu), pak se uloží její vzorový kód.
Uložení existujícího algoritmu, tj. takového, ke kterému existuje zdrojový soubor:
Save - pouze uloží uživatelem editovaný kód (všechny editované metody tohoto algoritmu) do zdrojového souboru algoritmu.
Save as - v tomto případě je nutné v dialogu pro uložení zadat nové jméno algoritmu. Vytvoří se kopie zdrojového souboru algoritmu s tímto novým jménem, do kopie se uloží uživatelem editovaný kód (všechny editované metody tohoto algoritmu) a změní se jméno algoritmu ve stromu algoritmů v manažeru algoritmů a jména záložek otevřených metod podle nového jména. Pokud byl tento algoritmus zaregistrován pod původním jménem, dojde k jeho odregistrování (tím ho nebude možné používat pro výpočty nad sítí, dokud nebude znovu otevřen a zkompilován, čímž se registrace provede znovu - více v kapitole 9.6 Kompilace kódu).
Poznámka: Soubor nelze obecně uložit pod implicitním jménem. Dojde k tomu pouze v případě, že se ukládá celý aktuální projekt. Tím se uživateli zajistí, že s projektem se uloží i algoritmy (s implicitními jmény), které ještě nebyly uloženy do zdrojových java-souborů. Ty lze pak sice otevřít ze zdrojových souborů, ale explicitně jim bude zrušena vazba na tento zdrojový soubor, takže opět (jako každý algoritmus s implicitním jménem) z pohledu aktuálního projektu nejsou uložené.
Možnosti:
Menu -> Algorithm -> Remove algorithm...,
Manažer algoritmů
-> tlačítko
![]() ,
,
Manažer algoritmů -> Kontextové menu -> Remove algorithm...
Uživatel
bude chtít algoritmus odstanit z projektu typicky v případě,
kdy už ho nebude potřebovat pro práci se sítí. Současně se mu tak
zpřehlední strom algoritmů v manažeru algoritmů, protože odstranění
algoritmu s sebou nese následující důsledky:
algoritmus se odstraní ze stromu algoritmů
algoritmus se odregistruje z projektu. To zajistí, že se pak neobjeví v žádné nabídce pro výběr algoritmu pro práci sítě (např. pro učení). Pokud by uživatel chtěl takový algoritmus opět používat v projektu, musí ho nejprve otevřít ze souboru a zkompilovat, což algoritmus opět zaregistruje - viz kapitola 9.6 Kompilace kódu.
Upozornění:
Odstraněním algoritmu z aktuálního projektu nedojde ke smazání
zdrojového souboru s tímto algoritmem!
Aby bylo možné editovat kód algoritmu, musí se nejprve takový algoritmus vytvořit či otevřít (viz předchozí kapitoly) a tím se zobrazí ve stromu algoritmů v manažeru algoritmů. Protože není možné editovat kód algoritmu jako celku ale jen jeho jednotlivých metod, musí se otevřít editor kódu příslušné metody. To lze tak, že se v manažeru algoritmů dvojklikne na metodu nebo se tato metoda přetáhne do požadované oblasti (Drag&Drop, více v kapitole 4.3 Manažer algoritmů). Editor algoritmů zajistí, že se pro každou metodu daného algoritmu otevře její editor, tj. editor metody, nejvýše jednou (pro dvě metody se stejným názvem dvou různých algoritmů se tak otevřou dva samostatné editory). Takový editor ukazuje obrázek níže:

Jak
již bylo zmíněno v úvodu kapitoly Algoritmy, vyžaduje se znalost
programování v jazyce Java. V tomto jazyce jsou také napsány všechny
zdrojové kódy metod uživatelských algoritmů. Základní pravidla a
návody pro psaní kódu jsou uvedeny v kapitole 9.7 Několik doporučení pro psaní uživatelských algoritmů.
Tento text je také přístupný formou nápovědy, kterou lze zobrazit
tlačítkem
![]() .
.
Popis
editoru metody
Editor se zobrazuje jako záložka v příslušné oblasti. Jméno záložky tvoří jméno algoritmu, kterému tato metoda přísluší. Následuje pomlčka a poté samotné jméno metody.
Pokud se zde navíc zobrazí symbol hvězdičky „*“, znamená to, že metoda byla od otevření editoru nebo od posledního uložení modifikována a provedené změny tedy ještě nebyly uloženy.
Tlačítka
Uložení
kódu
![]() -
uloží kód této metody do zdrojového souboru algoritmu. Pokud
algoritmus ještě nebyl nikdy uložen, zobrazí se nejprve dialog pro
uložení celého algoritmu. V tomto případě se všem ostatním metodám
uloží do tohoto nově vzniklého souboru jejich vzorový kód a této
metodě se uloží kód, který je v jejím editoru.
-
uloží kód této metody do zdrojového souboru algoritmu. Pokud
algoritmus ještě nebyl nikdy uložen, zobrazí se nejprve dialog pro
uložení celého algoritmu. V tomto případě se všem ostatním metodám
uloží do tohoto nově vzniklého souboru jejich vzorový kód a této
metodě se uloží kód, který je v jejím editoru.
Kompilace
kódu
![]() -
nejprve se uloží kód této metody do zdrojového souboru algoritmu.
Pokud tento soubor neexistuje, je postup stejný jako pro tlačíko
pro uložení kódu. Poté se provede kompilace celého algoritmu, tj. i
všech ostatních metod. Výsledek kompilace se zobrazí v panelu v
oblasti pro output. V případě chybného kódu vypíše
chybové hlášení týkající se jen této metody. Pokud byly v kódu
nalezeny další chyby, nezobrazí je a pouze o tom vypíše hlášení.
Pokud je kompilace úspěšná, dojde k zaregistrování příslušného
algoritmu. Více v kapitole 9.6 Kompilace kódu.
-
nejprve se uloží kód této metody do zdrojového souboru algoritmu.
Pokud tento soubor neexistuje, je postup stejný jako pro tlačíko
pro uložení kódu. Poté se provede kompilace celého algoritmu, tj. i
všech ostatních metod. Výsledek kompilace se zobrazí v panelu v
oblasti pro output. V případě chybného kódu vypíše
chybové hlášení týkající se jen této metody. Pokud byly v kódu
nalezeny další chyby, nezobrazí je a pouze o tom vypíše hlášení.
Pokud je kompilace úspěšná, dojde k zaregistrování příslušného
algoritmu. Více v kapitole 9.6 Kompilace kódu.
Undo
a redo
![]() ,
,
![]() -
umožňují vracet provedené úpravy v kódu buď zpět anebo vpřed.
-
umožňují vracet provedené úpravy v kódu buď zpět anebo vpřed.
Vzorový
kód
![]() -
smaže aktuální kód metody a nahradí ho svým vzorovým kódem.
-
smaže aktuální kód metody a nahradí ho svým vzorovým kódem.
I nformace
o metodě
nformace
o metodě
![]() -
otevře se dialog s kompletními informacemi o dané metodě. Dialog
vypadá takto:
-
otevře se dialog s kompletními informacemi o dané metodě. Dialog
vypadá takto:
V úvodu je jméno metody.
Další část obsahuje jméno algoritmu, kterému tato metoda přísluší, a cestu ke zdrojovému souboru algoritmu (pokud je cesta dlouhá, stačí do pole s cestou kliknout kurzorem a klávesami HOME a END na klávesnici se lze posunovat). Pokud algoritmus není uložen, zobrazí se popisek <not saved>.
Následující část dialogu obsahuje jméno abstraktního předka (tj. třída algoritmu) a jméno přímého předka (tj. buď rovněž třída algoritmu nebo vestavěný algoritmus - dle toho, jak byl algoritmus vytvářen, zda od abstraktní třídy, nebo od vestavěného algoritmu).
Tento výčet doplňuje informace o programátorské úrovni pro daný algoritmus.
Pak jsou v jednotlivých záložkách příslušné informace:
Popis metody.
Celkový, souhrnný popis třídy předka (tříd předků).
Popis metod třídy předka (tříd předků).
Popis datových struktur třídy předka (tříd předků), které lze využít při psaní algoritmu.
Pravidla
pro psaní kódu
![]() -
zobrazí případná další pravidla nebo omezení pro psaní kódu metod v
Javě. V obecném případě je možné, že tato nápověda bude prázdná.
-
zobrazí případná další pravidla nebo omezení pro psaní kódu metod v
Javě. V obecném případě je možné, že tato nápověda bude prázdná.
Hlavička
metody obsahuje návratovou hodnotu, jméno a vstupní parametry
metody. Pokud se nad ní najede kurzorem myši, po chvilce se objeví
popisek metody. Ten lze také najít v první záložce v dialogu s
informacemi o metodě (tlačítko
![]() ).
).
Tělo metody je umístěno v editovatelném textovém panelu. Kromě zmíněných tlačítek pro undo a redo lze k usnadnění editace použít kontextové menu, které se zobrazí po stisku pravého tlačítka myši nad tělem metody.
Následuje uzavírací závorka za tělem metody.
Pozici kurzoru zobrazuje dvojice čítačů ve formátu „číslo řádku“: „číslo sloupce“.
A nakonec statistické čítače určují celkový počet řádků v těle metody a jeho velikost v kB.
Možnosti:
Menu -> Algorithm -> Compile algorithm,
Manažer algoritmů
-> tlačítko
![]() ,
,
Manažer algoritmů -> Kontextové menu -> Compile algorithm,
Editor metody
-> tlačítko
![]() .
.
Na
žádost o kompilaci kódu (viz možnosti výše) se vždy provede
kompilace celého zdrojového kódu algoritmu bez ohledu na to, zda
jsme žádost o kompilaci vysílali z panelu algoritmů nebo z editoru
metody. Rozdíl je jen v tom, co se uloží před samotnou kompilací:
Kompilace z editoru metody - uloží se aktuální kód metody (více v kapitole 9.5 Editor algoritmů).
Ostatní kompilace - uloží se kódy všech editovaných metod (tj. těch, které mají otevřen editor).
Informace
o provedené kompilaci se zobrazí v oblasti Output. Jméno
záložky je tvořeno slovem „Compilation“, následuje
pomlčka a jméno algoritmu, který se kompiluje.
Možné
výsledky kompilace jsou následující:
Úspěšná kompilace
v textovém poli se zobrazí text 0 errors,
a současně se daný algoritmus zaregistruje k použití při práci sítě.

Neúspěšná kompilace 1
Kompilace z editoru metody
Pokud je chyba v jiné metodě, než v té, z které spouštíme kompilaci, zobrazí se informace o existující chybě. Dále se vypíše výstup standardního Sun Java kompilátoru bez dalšího formátování.
Pokud je chyba v této metodě, pak se zobrazí stručný výpis o všech chybách, které našel Sun Java kompilátor v této metodě - výstup Sun Java kompilátoru je zformátován:
LINE - číslo řádku v editoru metody,
MSG - chybové hlášení kompilátoru,
CODE - část kódu, kde se daná chyba nachází.

Neúspěšná kompilace 2
Pokud se kompilace spouští odjinud, pak se zobrazí pouze informace o tom, že se v některé metodě vyskytla chyba. Dále se vypíše výstup standardního Sun Java kompilátoru.

V případě úspěšné kompilace algoritmu, tj. v kódu není žádná chyba, dojde automaticky k tzv. zaregistrování algoritmu. Zjednodušeně řečeno jde o proces, kdy se programu iSNS „řekne“, že pro práci se sítí (např. tedy k učení) lze použít nějaký nový algoritmus. Programu se řekne jméno tohoto algoritmu a ukáže se mu na příslušnou třídu (class-soubor), která vznikne právě pouze po úspěšném překladu kódu, tj. po úspěšné kompilaci.
Pokud je algoritmus již zaregistrovaný a při následující kompilaci se v kódu vyskytne chyba, zůstává v programu zaregistrovaná stará verze algoritmu.
Po odstranění algoritmu z aktuálního projektu (viz kapitola 9.4 Odstranění algoritmu) se provede odregistrování takového algoritmu. Algoritmus, který tedy není zaregistrován, nemůže být použit pro práci sítě, protože o něm program vůbec neví.
Položkami přístupnými z programu myslíme takové datové položky algoritmu, které může uživatel sledovat pomocí vizualizačních modulů, případně měnit jejich hodnoty v panelu algoritmu (viz např. kapitola 7.4.5 Sítě typu Backpropagation - Učení). Takové položky též někdy nazýváme parametry algoritmu. Parametr algoritmu podobně jako jakoukoliv jinou položku je možno založit ve vyhrazeném prostoru FREE ZONE. Parametr je vlastně obyčejná položka s právy přístupu public s přidanou anotací UserAccess. Parametry mohou být určeny pro zápis, nebo pouze pro čtení.
Parametr určený pro zápis (např. typu int) založíme v kódu pomocí:
@UserAccess public int cislo;
pro přidání vlastnosti pouze pro četní je třeba psát:
@UserAccess(readOnly=true) public int cislo;
U algoritmů běžících ve vlastním vlákně (potomků tříd BPLearning, KohonenLearning a Recollection) je pro zajištění možnosti krokování v kódu nutné definovat určitá místa – tzv. synchronizační body, na kterých se výpočet může zastavit. Taková místa většinou představují okamžiky, kdy algoritmus dokončil určitou výpočetní fázi (epochu) a je připraven nechat uživatele shlédnout mezivýsledky. V kódu jsou tato místa označena voláním metody synchronize. Metoda synchronize, ve skutečnosti zděděná od společného předka Algorithm, vyžaduje při zavolání dva parametry – číslo epochy (typu int) a mód krokování (typu StepMode).
Číslo epochy udává, kolikátá výpočetní fáze zrovna skončila. Jelikož je plně v režii programátora, vytvářejícího daný algoritmus, určit si, co to přesně výpočetní fáze je, záleží tedy jen na něm, s jakým číslem epochy metodu synchronize zavolá. Ve výsledku tím ovlivní především vizualizační moduly, které sledují průběh určitého parametru algoritmu, neboť právě číslo epochy je údaj, který určuje x-ovou souřadnici do grafu vynášených hodnot.
Druhým parametrem je mód krokování. Jedná se o parametr typu StepMode, což je výčtový typ definovaný uvnitř třídy Algorithm (a tedy přístupný z kódu algoritmů, o kterých je právě řeč). Může nabývat tří různých hodnot: StepMode.MICRO, StepMode.NORMAL a StepMode.MACRO; a opět jeho konkrétní použití závisí na uvážení programátora. Při krokování algoritmu (viz např. kapitola 7.4.5 Sítě typu Backpropagation - Učení), které může probíhat ve třech módech MICRO, NORMAL a MACRO, se totiž bere zřetel právě na synchronizační body definované voláním metody synchronize s tím parametrem, který odpovídá módu krokování algoritmu.
Návratovou hodnotou typu boolean metoda synchronize oznamuje, zda nemá dojít k přerušení běhu algoritmu. Během pauzy v provádění algoritmu vzniklé voláním metody synchronize si totiž může uživatel usmyslet, že chce algoritmus ukončit. Programátor algoritmu se o tom dozví tím, že metoda synchronize vrátí návratovou hodnotou true, a měl by provádění výpočtů co nejrychleji ukončit, případně i za cenu, že výpočet nebude zcela dokončen.
Celkově vzato definuje tedy algoritmus zavoláním metody synchronize synchronizační bod, což je okamžik, kdy může být provádění výpočtu pozastaveno a kdy si vizualizační moduly zjišťují aktuální hodnoty sledovaných parametrů. Použití metody synchronize by mohlo vypadat například takto:
for (int epoch = 0; epoch < maxSteps; epoch++) {
doSomething();
if (synchronize(epoch,StepMode.NORMAL))
break;
}
Vytvoření sítě:
Klikněte na
tlačítko
![]() v manažeru sítí nebo v menu Network vyberte položku Create
network...
v manažeru sítí nebo v menu Network vyberte položku Create
network...
V dialogu zvolte jméno sítě (např. myNetwork).
Jako model vyberte Backpropagation net.
Chceme síť se čtyřmi vrstvami a s počty neuronů ve vrstvách 2,3,3,1 - tedy se dvěma vstupními neurony a jedním výstupním a se dvěma skrytými vrstvami po třech neuronech. Proto v Number of Layers zvolte 4 a následně vyplňte tabulku „Numbers of Neurons in Layers“.
Pro inicializaci vah zvolte např. normální rozdělení se střední hodnotou 0 a odchylkou 1.5.
Stiskněte tlačítko OK.
Dvojklikněte na jméno sítě (myNetwork) v manažeru sítí, aby se zobrazila její záložka na hlavní ploše.
Vytvoření dat
Klikněte
na tlačítko
![]() v
manažeru dat nebo v menu Data vyberte položku New data.
v
manažeru dat nebo v menu Data vyberte položku New data.
V dialogu zvolte jméno datové proměnné pro vstup (např. orInput).
Jako typ dat zvolte „matrix of double“.
Height bude 4 (počet vstupních vektorů) a Width bude 2 (délka vstupních vektorů).
Stiskněte tlačítko OK.
Stejným způsobem vytvořte i proměnnou pro požadované výstupy. Její rozměry budou 4*1 (Height 4, Width 1) a jméno orOutput.

Dvojklikněte na jméno datové proměnné (orInput a orOutput) v manažeru dat, aby se zobrazila její záložka na hlavní ploše.
Vyplňte hodnoty matic tak, aby odpovídaly logické funkci „or“.
Učení
Otevřete
si záložku sítě (dvojklikem na jméno proměnné sítě v manažeru sítí)
a klikněte na tlačítko
![]() .
.
V dialogu zvolte algoritmus MyBPLearning, jako vstupy orInput a jako požadované výstupy orOutput.
Stiskněte OK.

Objeví se dvě nové záložky. Abyste mohli vidět všechny najednou, klikněte pravým tlačítkem na záložkový proužek a v menu zvolte Separate horizontally.
D o
vzniklého prostoru dole přetáhněte záložku s učícími daty
(myNetwork learning set). Znovu klikněte na ouško záložky pravým
tlačítkem a zvolte Separate vertically. Do vzniklého
prostoru vpravo přetáhněte záložku s algoritmem (myNetwork
algorithm).
o
vzniklého prostoru dole přetáhněte záložku s učícími daty
(myNetwork learning set). Znovu klikněte na ouško záložky pravým
tlačítkem a zvolte Separate vertically. Do vzniklého
prostoru vpravo přetáhněte záložku s algoritmem (myNetwork
algorithm).
V záložce s algoritmem nastavte stepMode na MICRO. Při stisknutí
tlačítka
![]() se
pak vždy provede krok učení pro jeden vzor. Můžete sledovat změny
sítě v záložce sítě. Pokud chcete znát např. hodnotu nějaké
konkrétní váhy, klikněte na neuron, do něhož tato váha vede. Pole
vah vedoucích do označeného neuronu se zobrazí pod sítí. Ostatní
charakteristiky označeného neuronu se zobrazí vpravo od sítě.
Hodnoty je možné také měnit.
se
pak vždy provede krok učení pro jeden vzor. Můžete sledovat změny
sítě v záložce sítě. Pokud chcete znát např. hodnotu nějaké
konkrétní váhy, klikněte na neuron, do něhož tato váha vede. Pole
vah vedoucích do označeného neuronu se zobrazí pod sítí. Ostatní
charakteristiky označeného neuronu se zobrazí vpravo od sítě.
Hodnoty je možné také měnit.
Pro
naučení sítě zvolte stepMode NORMAL, nastavte numSteps např. na
1000 a stiskněte tlačítko
![]() .
Provede se 1000 kroků algoritmu pro každý vzor. Chyba sítě se
vypisuje v oblasti Output ve spodní části obrazovky.
.
Provede se 1000 kroků algoritmu pro každý vzor. Chyba sítě se
vypisuje v oblasti Output ve spodní části obrazovky.
Chcete-li
učení opakovat stiskněte znovu tlačítko
![]() .
Můžete samozřejmě nastavit jiný počet kroků, nebo v položce
errorThreshold napsat číslo, pod které když klesne chyba, se má běh
algoritmu ukončit.
.
Můžete samozřejmě nastavit jiný počet kroků, nebo v položce
errorThreshold napsat číslo, pod které když klesne chyba, se má běh
algoritmu ukončit.
Pokud
chcete začít s učením od začátku (např. proto, že síť už je
přeučená), stiskněte tlačítko
![]() .
Váhy sítě se znovu inicializují (tj. síť „zapomene“
vše, co se naučila!).
.
Váhy sítě se znovu inicializují (tj. síť „zapomene“
vše, co se naučila!).
Zde si ukážeme několik příkladů jak změnit nějaký parametr sítě.
Máme otevřenou síť typu Backpropagation a chceme změnit práh třetího neuronu druhé vrstvy.
Klikněte na vybraný neuron.
Vpravo od sítě se objeví panel s informacemi o neuronu. Dvojklikněte do políčka pod nápisem bias a změňte hodnotu, kterou obsahuje.
Poznámka: Pokud je vizualizovaná síť v původní poloze (tj. na začátku po otevření nebo po dvojkliku na vizualizátor), jsou vrstvy číslovány zleva doprava a neurony ve vrstvách zdola nahoru.
Jiná možnost:
V manažeru sítí klikněte na jméno sítě se stisknutou klávesou Shift.
Klikněte na tlačítko pod nápisem neurons.
Zobrazí se jednořádková tabulka tlačítek. Klikněte na druhé z nich (odpovídá druhé vrstvě).
Zobrazí se opět jednořádková tabulka tlačítek. Klikněte na třetí z nich (odpovídá třetímu neuronu).
Zobrazí se panel s informacemi o neuronu. Dvojklikněte do políčka pod nápisem bias a změňte hodnotu, kterou obsahuje.
Máme otevřenou síť typu Backpropagation a chceme změnit váhu mezi druhým neuronem první (vstupní) vrstvy a třetím neuronem druhé vrstvy.
Klikněte na třetí neuron druhé vrstvy (tj. neuron do něhož vybraná váha vede).
Pod sítí se objeví jednořádková tabulka. Dvojklikněte do druhé buňky a změňte hodnotu, kterou obsahuje.
Jiná možnost:
V manažeru sítí klikněte na jméno sítě se stisknutou klávesou Shift.
Klikněte na tlačítko pod nápisem weights.
Zobrazí se jednořádková tabulka tlačítek. Klikněte na první z nich (odpovídá vrstvě vahám z první do druhé vrstvy).
Zobrazí se tabulka čísel. Číslo ve třetím řádku ve druhém sloupci odpovídá vybrané váze - dvojklikněte do buňky a vepište novou hodnotu.
Klikněte na neuron jehož přechodovou funkci chcete upravit.
V panelu s informacemi o neuronu vpravo od sítě klikněte na tlačítko pod nápisem transferFunction.
Pokud má přechodová funkce parametr, zobrazí se v panelu jeho název a políčko s hodnotou, kterou je možné přepsat na jinou.
Poznámka: Ne každá přechodová funkce má parametr, který by se dal měnit. Z vestavěných přechodových funkcí má parametr funkce Logsig.
Jiná možnost:
V manažeru sítí klikněte na jméno sítě se stisknutou klávesou Shift.
Klikněte na tlačítko pod nápisem neurons.
Vyberte požadovanou vrstvu a požadovaný neuron - viz výše v kapitole 10.2.1 Změna prahu určitého neuronu.
V panelu s informacemi o neuronu vpravo od sítě klikněte na tlačítko pod nápisem transferFunction.
Pokud má přechodová funkce parametr, zobrazí se v panelu jeho název a políčko s hodnotou, kterou je možné přepsat na jinou.
Během učení mají vizualizační moduly přístup do interních proměnných algoritmů. Jak toho využít si ukážeme na několika vizualizacích.
Návod předpokládá načtenou Backpropagation síť, vstupní/výstupní data pro učení a otevřené učení - např. pomocí návodu 10.1 Vytvoření sítě a dat a naučení funkce nebo načtením projektu Tutorial_OR z adresáře projects.
V kontextovém menu pro Backpropagation síť s aktivním učením zvolte Error visualization. Vytvoří se čárový graf (XY Line Chart) a přidá se jako nová záložka do hlavní oblasti. Pokud nevidíte zároveň záložky pro ovládání algoritmu a nový vizualizační modul, doporučuji přesunout záložky a případně rozdělit oblast tak, aby jste viděli obojí naráz.
Vizualizační modul je již napojený na proměnnou error učícího algoritmu, ale čeká na spuštění algoritmu. Pro rychlejší průběh vizualizace je doporučeno zvolit stepMod: MACRO a macroStep: 10 (nebo větší) - do vizualizačního modulu pak nebudou posílána data v každém kroku algoritmu. Vzhledem k tomu, že se provádí řádově tisíce kroků algoritmu, bude i při použití macroStep průběh grafu hladký.
Po spuštění algoritmu tlačítkem
![]() můžete sledovat průběh chybové funkce na záložce vizualizačního
modulu:
můžete sledovat průběh chybové funkce na záložce vizualizačního
modulu:

Vytvoření 3D sloupcového grafu (vizualizačního modulu BarChart Array 3D) pro výstup 2. vrstvy sítě:
v menu Visualization zvolte Add BarChart Array 3D...,
v okně „Select the desired field“ rozbalte pomocí + položku networkManager -> data -> název sítě -> neurons,
dvojklikněte na položku [1] (2. vrstva sítě),
v novém dialogu zvolte output (výstup neuronu),
stiskněte OK.
Graf
bude obsahovat tolik sloupců, kolik obsahuje vybraná vrstva neuronů.
Po
spuštění algoritmu tlačítkem
![]() můžete
v průběhu algoritmu sledovat změny výstupů jednotlivých neuronů
(měnící se výšky sloupců):
můžete
v průběhu algoritmu sledovat změny výstupů jednotlivých neuronů
(měnící se výšky sloupců):

Přesné údaje o výstupu určitého neuronu lze zobrazit pomocí bublinkové nápovědy, která se zobrazí, pokud chvíli počkáte s kurzorem myši nad určitým sloupcem. Index sloupce určuje, o neuron ve vybrané vrstvě se jedná.
Poznámka: Výstup koresponduje s 3D náhledem sítě, kde jsou modře vyznačeny neurony s nejmenším výstupem, červeně s největším výstupem a ostatní odpovídajícími odstíny z přechodu od modré k červené.
Zde si předvedeme, jak program iSNS obohatit o vlastní přechodovou funkci a jak tuto funkci použít. Vybraná funkce je dána předpisem:
f(x) = x pro x>=0
f(x) = 0 pro x<0
V
manažeru algoritmů stiskněte tlačítko
![]() .
V dialogu vyberte
.
V dialogu vyberte
typ algoritmu TransferFunction,
Programmer level Normal
a stiskněte OK.

Nový algoritmus se zobrazí v manažeru algoritmů s názvem _new_1. Pod ním jsou ve stromu algoritmů položky function a derivative. Protože se při učení používá derivace přechodové funkce, je nutné s každou přechodovou funkcí (function) vytvořit i funkci její derivace (derivative).
Dvojklikněte nejprve na položku function. Otevře se editor algoritmů pro přechodovou funkci. Zde napište kód přechodové funkce, tedy v našem případě
if (x>=0) return x;
else return 0.0;
Nyní
funkci zkompilujte - stiskněte tlačítko
![]() Zobrazí
se nejprve dialog pro uložení. V něm zvolte jméno souboru pro novou
přechodovou funkci - např. poslin_transfer a stiskněte OK. V manažeru
algoritmů se místo _new_1 zobrazí název vybraného souboru a po
proběhnutí kompilace funkce function se zobrazí v oblasti
Output v záložce s kompilací text
Zobrazí
se nejprve dialog pro uložení. V něm zvolte jméno souboru pro novou
přechodovou funkci - např. poslin_transfer a stiskněte OK. V manažeru
algoritmů se místo _new_1 zobrazí název vybraného souboru a po
proběhnutí kompilace funkce function se zobrazí v oblasti
Output v záložce s kompilací text
0 errors
Nyní je potřeba vytvořit ještě funkci pro derivaci. Pro otevření editoru s derivací dvojklikněte na položku derivative. Zde napište kód pro derivaci. V našem případě to je
if(x>=0) return 1.0;
else return 0.0;
Stiskněte
opět tlačítko
![]() pro
zkompilování funkce derivative. Dialog pro uložení už se
nezobrazí, algoritmus už se automaticky ukládá do vybraného souboru.
V oblasti Output v záložce s kompilací se opět zobrazí text
pro
zkompilování funkce derivative. Dialog pro uložení už se
nezobrazí, algoritmus už se automaticky ukládá do vybraného souboru.
V oblasti Output v záložce s kompilací se opět zobrazí text
0 errors
Teď
už je možné novou funkci použít. Otevřete si síť typu Backpropagation
(kliknutím na
![]() a výběrem vhodné sítě, nebo vytvořte novou - viz např. tutoriál 10.1
Vytvoření sítě a dat a naučení funkce ).
a výběrem vhodné sítě, nebo vytvořte novou - viz např. tutoriál 10.1
Vytvoření sítě a dat a naučení funkce ).
Kliknutím označte neuron, kterému chcete změnit přechodovou funkci. V panelu vpravo od sítě vyberte v transferFunctionType nově vytvořenou funkci poslin_transfer.

Vybraný neuron má teď novou přechodovou funkci, která se bude používat při výpočtu výstupu a učení.
Nyní upravíme funkci vytvořenou v předchozím tutoriálu tak, aby měla parametr, který může uživatel měnit. Předpis bude
f(x) = ax pro x>=0
f(x) = 0 pro x<0
V manažeru algoritmů stiskněte tlačítko
![]() .
.
V dialogu vyberte soubor poslin_transfer.java a stiskněte tlačítko Open.

Nejprve dvojklikněte na Free_Zone v manažeru algoritmů. Otevře se okno editoru.
Do něj vepište kód
@UserAccess public double a = 1;
Tím se vytvoří uživatelský parametr typu double s názvem a a s hodnotou 1.
Tento zdrojový text zkompilujte stiskem tlačítka
![]() .
.
Nyní si dvojkliknutím na function v manažeru algoritmů otevřete editor. Měl by obsahovat původní zdrojový text vytvořený v předchozím tutoriálu, který stačí drobně pozměnit. Nový program bude
if (x>=0) return a*x;
else return 0.0;
Zkompilujte ho opět pomocí tlačítka
![]() .
.
Stejným způsobem pozměňte a zkompilujte také derivaci:dvojklikněte na derivative a text pozměňte na
if(x>=0) return a;
else return 0.0;
Po
zkompilování
![]() je
nová přechodová funkce připravena k použití a můžete si ji tedy
vyzkoušet.
je
nová přechodová funkce připravena k použití a můžete si ji tedy
vyzkoušet.
Otevřete si síť typu Backpropagation a klikněte na některý neuron.
V panelu vpravo od sítě vyberte v transferFunctionType nově funkci poslin_transfer.
V tomtéž panelu stiskněte tlačítko se třemi tečkami pod nápisem transferFunction.

Objeví se panel obsahující název parametru (v našem případě a) a jeho hodnotu, která je nastavena na 1 a lze ji měnit.

Předvedeme si pozměnění učícího algoritmu pro sítě typu Backpropagation a obohatíme vestavěný algoritmus o moment. To znamená, že kromě aktuální hodnoty gradientu chybové funkce budeme brát v úvahu i předchozí změny vah. Setrvačnost takovému algoritmu pomůže zamezit extrémním oscilacím v „úzkých údolích chybové funkce“.
Náš
nový algoritmus odvodíme od třídy MyBPLearning a použijeme
programátorskou úroveň NORMAL. V manažeru algoritmů stiskneme
![]() ,
provedeme zmíněné volby v dialogovém okně a potvrdíme tlačítkem
OK.
,
provedeme zmíněné volby v dialogovém okně a potvrdíme tlačítkem
OK.

Nový
algoritmus se zobrazí v manažeru algoritmů např. s názvem _new_1.
Pod ním jsou ve stromu algoritmů položky learnSetInit,
computeDeltas, learnSetFinalize a Free_Zone.
Nejprve budeme chtít nadefinovat datové struktury pro uložení minulých hodnot vah a prahů a nový učící parametr určující vliv momentu na učení. Otevřeme proto editor algoritmů pro oblast Free_Zone dvojklikem na její uzel ve stromě manažeru algoritmů a do editoru zapíšeme potřebný kód – v našem případě:
protected double[][][] weightDeltasOld = null;
protected double[][] biasDeltasOld = null;
@UserAccess public volatile double alphaM = 0.3;
Nyní je ještě potřeba předefinovat metodu learnSetFinalize pro zajištění fungování práce s momentem. V manažeru algoritmů poklepeme na tuto položku a do editoru vložíme následující kód.
if (weightDeltasOld != null) {
for(int l = 0; l< weightDeltasOld.length; l++)
for (int i = 0; i<weightDeltasOld[l].length; i++)
for (int j = 0; j<weightDeltasOld[l][i].length; j++)
weightDeltas[l][i][j] += alphaM*weightDeltasOld[l][i][j];
for (int i = 0; i < biasDeltasOld.length; i++)
for(int j = 0; j < biasDeltasOld[i].length; j++)
biasDeltas[i][j] += alphaM*biasDeltasOld[i][j];
}
adjustWeightBiasDeltas();
//swap
double[][][] tmp1 = weightDeltasOld;
weightDeltasOld = weightDeltas;
weightDeltas = tmp1;
double[][] tmp2 = biasDeltasOld;
biasDeltasOld = biasDeltas;
biasDeltas = tmp2;
Těsně před tím, než jsou spočtené změny weightDeltas a biasDeltas zapsány do sítě pomocí adjustWeightBiasDeltas, upraví nový algoritmus jejich hodnoty o příspěvek změn z minulé iterace weightDeltasOld a biasDeltasOld. Jejich vliv závisí na parametru alphaM. Následně jsou nové hodnoty uloženy pro použití v příští iteraci.
Kód ostatních metod necháme beze změny.
Nyní
je možné nový algoritmus zkompilovat – použijeme k tomu
tlačítko
![]() .
Zobrazí se nejprve dialog pro uložení. V něm zvolte jméno souboru pro
nový algoritmus - např. BPMoment a stiskněte OK. V
manažeru algoritmů se místo _new_1 zobrazí název vybraného
souboru a po proběhnutí kompilace algoritmu se zobrazí v oblasti
Output v záložce s kompilací text
.
Zobrazí se nejprve dialog pro uložení. V něm zvolte jméno souboru pro
nový algoritmus - např. BPMoment a stiskněte OK. V
manažeru algoritmů se místo _new_1 zobrazí název vybraného
souboru a po proběhnutí kompilace algoritmu se zobrazí v oblasti
Output v záložce s kompilací text
0 errors
Teď
už je možné nový algoritmus použít. Otevřete si síť typu
Backpropagation (kliknutím na ![]() a
výběrem vhodné sítě nebo vytvořte novou - viz např. tutoriál 10.1Vytvoření sítě a dat a naučení funkce OR).
a
výběrem vhodné sítě nebo vytvořte novou - viz např. tutoriál 10.1Vytvoření sítě a dat a naučení funkce OR).
V dialogu pro učení sítě nyní bude možné vybrat si nový algoritmus.

Také
si můžeme všimnout nového parametru algoritmu alpha v panelu
učení sítě, jehož hodnota určuje míru vlivu momentu při učení.

Chceme rozdělit vstupní data do dvou skupin na základě jejich podobnosti. K určení, která data patří k sobě, nám poslouží Kohonenova mapa.
Vytvoření dat:
klikněte na tlačítko
![]() v
manažeru dat;
v
manažeru dat;
v dialogu New variable zadejte
Name: data,
Type: matrix of double,
Height: 5,
Width: 6
a stiskněte tlačítko OK.

Nyní
v manažeru dat dvojklikněte na vytvořenou datovou proměnnou data,
otevře se editor dat. Zadejte následující vstupní vektory:
1.0, 1.0, 1.0, 1.0, 1.0, 1.0
1.0, 0.0, 1.0, 0.0, 1.0, 0.0
0.0, 0.0, 1.0, 0.0, 0.0, 0.0
-1.0, -1.0, -1.0, 0.0, 0.0, -1.0
-1.0, -1.0, -1.0, -1.0, -1.0, -1.0
Vytvoření sítě:
klikněte na tlačítko
![]() v
manažeru sítí;
v
manažeru sítí;
v dialogu New net zadejte
Name: Kohonenova_mapa,
Model: Kohonen net,
Number of Input Neurons: 6,
Height of Output Neurons Grid: 6,
Width of Output Neurons Grid: 4
a stiskněte tlačítko OK.

V
manažeru sítí klikněte na vytvořenou síť Kohonenova_mapa; zobrazí se
panel Kohonenovy mapy, kde klikněte na tlačítko učení
![]() .
V dialogu Learning Kohonen net vyberte:
.
V dialogu Learning Kohonen net vyberte:
Algorithm: MyKohonenLearning,
Input: Data,
a stiskněte tlačítko OK.
Objeví se:
panel s učícími daty (Kohonenova_mapa learning set),
ovládací panel učícího algoritmu (Kohonenova_mapa algorithm),
panel s výstupy v oblasti Output (Kohonenova_mapa learning).
Učení:
je vhodné rozdělit pracovní plochu na více oblastí, aby byly panel Kohonenovy mapy, panel s učícími daty a ovládací panel učení vidět současně,
klikněte pravým tlačítkem myši na řádek se záložkami (Kohonenova_mapa, ...) a zvolte Separate vertically,
totéž ještě jednou, ale zvolte Separate horizontally,
pracovní plocha se tak rozdělí na tři oblasti, kam můžete přetažením (Drag&Drop) záložek přenést jednotlivé panely;

stiskněte tlačítko
![]() ,
kterým spustíte učení.
,
kterým spustíte učení.
Výsledek učení (tj. vítězné výstupní neurony) může vypadat např. takto (v závislosti na počáteční inicializaci vah):

Nyní
proveďte klastrování:
v panelu Kohonenovy mapy klikněte na
![]() ;
;
objeví se panel klastrování:
nastavte Clusters count na 2,
zatrhněte Show distances
a klikněte na tlačítko Do clustering.

Výsledek
klastrování může být např. (v závislosti na počáteční inicializaci
vah):
Cluster #1: 2, 4, 9, 8, 1, 5, 0
Cluster #2: 15, 19, 23, 11, 16, 18, 3, 7, 12, 22, 17, 13, 21, 6, 20, 14, 10
Na vektory
1.0, 1.0, 1.0, 1.0, 1.0, 1.0
1.0, 0.0, 1.0, 0.0, 1.0, 0.0
0.0, 0.0, 1.0, 0.0, 0.0, 0.0
reagují neurony 7, 23, 13, patřící do klastru 2; na vektory
-1.0, -1.0, -1.0, 0.0, 0.0, -1.0
-1.0, -1.0, -1.0, -1.0, -1.0, -1.0
reagují neurony 1, 0, patřící do klastru 1.
Rozdělení neuronů do klastrů dává rozdělení vstupních vektorů.
Nejprve bude potřeba připravit uživatelské proměnné s obrázky znaků:
V menu Data vyberte Import data -> Picture...
Objeví se standardní dialog pro výběr souboru:
V podadresáři pictures adresáře s programem iSNS se nalézají obrázky znaků.
Vyberte obrázek a.gif a stiskněte tlačítko Open.
Celou proceduru ještě dvakrát zopakujte a nahrajte též obrázky se znaky b.gif a c.gif.
Druhým krokem je vytvoření nové sítě typu Hopfield:
klikněte na tlačítko
![]() v
manažeru sítí,
v
manažeru sítí,
v dialogu New net zadejte
Name: mujHopfield,
Model: Hopfield net,
Height of Neuron Grid: 22,
Width of Neuron Grid: 22
a stiskněte tlačítko OK.
Poznámka: Rozměry nově vytvořené sítě (22x22) byly zvoleny tak, aby odpovídaly rozměrům obrázků znaků, se kterými se bude pracovat.
Otevření
panelu sítě a naučení vzorů:
v manažeru sítí klikněte na vytvořenou síť mujHopfield;
zobrazí se panel
pro práci se sítí typu Hopfield, kde klikněte na tlačítko učení
![]() ;
;
V dialogu Select vectors to learn... vyberte s pomocí klávesy Ctrl všechny tři proměnné
a stiskněte tlačítko OK
Nastavení
počátečního vzoru a přidání šumu:
Počáteční vzor nastavte pomocí tlačítka
![]() .
.
V dialogu Select vector to set the current to... označte proměnnou A
a stiskněte tlačítko OK
Zašumění vzoru
vyvolejte (případně několikanásobným) stiskem tlačítka
![]()
Program by mohl nyní vypadat například takto:

Spuštění
vybavování a úprava uživatelské plochy:
v panelu sítě stiskněte tlačítko
![]() ,
,
v dialogu Select algorithm for recollection... vyberte algoritmus MyRecollection
a stiskněte tlačítko OK.
Je vhodné rozdělit pracovní plochu na více oblastí, aby bylo možno panel se sítí a panel s vybavováním sledovat současně:
klikněte pravým tlačítkem myši na řádek se záložkami (mujHopfield, ...) a zvolte Separate vertically;
na pracovní ploše se tak objeví nová oblast, kam bude možno přetažením záložky přenést (Drag&Drop) nový panel s vybavováním.
Vybavování
můžete nyní spustit tlačítkem
![]() a
potom sledovat, jak se postupně zašuměný vzor „zbavuje kazů”,
až se nakonec objeví původní písmeno A.
a
potom sledovat, jak se postupně zašuměný vzor „zbavuje kazů”,
až se nakonec objeví původní písmeno A.
Materiály k přednášce z předmětu AIL002 Neuronové sítě na MFF UK (http://ksvi.mff.cuni.cz/~mraz/nn/slides/),
V. Mařík, O. Štěpánková, J. Lažanský a kol.: Umělá Inteligence (1). Academia, Praha, 1993,
Introduction to Neural Networks with Java (http://www.heatonresearch.com/articles/series/1/),
Self-organizing map, wikipedie (http://en.wikipedia.org/wiki/Self-organizing_map),
Neural Networks Web Site, University of Birmingham (http://www.cs.bham.ac.uk/~jlw/sem2a2/Web/Kohonen.htm),
Data clustering, wikipedie (http://en.wikipedia.org/wiki/Data_clustering).
New project
Vytvoří nový projekt, aktuální projekt se zavře.
Open project...
Otevře uložený projekt, aktuální projekt se zavře.
Save project
Uloží aktuální projekt.
Save project as...
Uloží aktuální projekt pod novým jménem.
Exit
Ukončí iSNS.
Create data...
Vytvoří novou datovou proměnnou - vektor typu double, matice typu double nebo Hopfield picture.
Load data...
Načte uloženou datovou proměnnou ze souboru.
Save data
Uloží vybranou datovou proměnnou do souboru (je-li pojmenovaná, jinak viz Save data as...).
Save data as...
Uloží vybranou datovou proměnnou do souboru pod novým jménem.
Export data
Uloží vybranou datovou proměnnou do souboru ve formátu XML, CSV nebo obrázek.
Import data
Načte datovou proměnnou ze souboru ve formátu XML, CSV nebo obrázek.
Remove data
Odstraní vybranou datovou proměnnou.
Create network...
Vytvoří novou síť.
Load network
Načte uloženou síť ze souboru.
Save network
Uloží vybranou síť do souboru (je-li pojmenovaná, jinak viz Save network as...).
Save network as...
Uloží vybranou síť do souboru pod novým jménem.
Save version
Uloží pro vybranou síť verzi.
Set current version
Nastaví vybranou síť jakou aktuální verzi.
View/edit label
Zobrazí/umožní editovat popisek verze.
Error visualization
Vytvoří vizualizační modul XY Line Chart, který sleduje průběh chyby učícího algoritmu sítě Backpropagation.
Remove network
Odstraní vybranou síť.
Create algorithm...
Vytvoří nový algoritmus.
Load algorithm...
Načte již existující algoritmus ze souboru.
Save algorithm
Uloží zvolený algoritmus do souboru, tj. uloží všechny právě editované metody tohoto algoritmu.
Save algorithm as...
Uloží zvolený algoritmus, tj. uloží všechny jeho právě editované metody do nového souboru a v projektu se tento algoritmus objeví pod novým jménem.
Compile algorithm
Uloží celý algoritmus, tj. všechny jeho právě editované metody, a zkompiluje ho.
Remove algorithm...
Odebere algoritmus z projektu. Neodstraní však jeho zdrojový soubor.
Všechny menu položky v menu Visualization vytvářejí vizualizační modul daného typu - pro uživatelem zvolené sledované proměnné či pole dat (tzv. Array vizualizace).
Add Simple Label...
Vytvoří jednoduchý vizualizační modul pro sledování současné hodnoty proměnné číslem.
Add XY Line Chart...
Vytvoří čárový graf pro sledování průběhu hodnoty proměnné v závislosti na kroku algoritmu.
Add XY Area Chart...
Vytvoří plošný graf pro sledování průběhu hodnoty proměnné v závislosti na kroku algoritmu.
Add XY Step Chart...
Vytvoří čárový graf pro sledování průběhu hodnoty proměnné v závislosti na kroku algoritmu (skokem).
Add Bar Chart...
Vytvoří sloupcový graf pro sledování průběhu hodnoty proměnné v závislosti na kroku algoritmu.
Add Bar Chart 3D...
Vytvoří 3D sloupcový graf pro sledování průběhu hodnoty proměnné v závislosti na kroku algoritmu.
Add Bar Chart Array...
Vytvoří sloupcový graf pro sledování současných hodnot jednotlivých prvků pole.
Add Bar Chart Array 3D...
Vytvoří 3D sloupcový graf pro sledování současných hodnot jednotlivých prvků pole.
Add Pie Chart Array...
Vytvoří koláčový graf pro sledování současných hodnot jednotlivých prvků pole.
Add Pie Chart Array 3D...
Vytvoří 3D koláčový graf pro sledování současných hodnot jednotlivých prvků pole.
Add TimeSeries Line Chart...
Vytvoří čárový graf pro sledování průběhu hodnoty proměnné v závislosti na čase.
Add TimeSeries Area Chart...
Vytvoří plošný graf pro sledování průběhu hodnoty proměnné v závislosti na čase.
Add TimeSeries Step Chart...
Vytvoří čárový graf pro sledování průběhu hodnoty proměnné v závislosti na čase (skokem).
About
Seznam autorů a WWW adresa projektu.
